即刻App年轻人的同好社区
下载
我觉得很多人可能没意识到,llama3将以怎样的速度促进企业级LLM应用的广泛落地。
之前大家总讨论为什么在中国企业级的大语言模型应用似乎没怎么实现落地和普及,核心原因之一就是开源模型的能力与gpt4之间巨大的差异。
而llama3的出现,让100%本地化RAG更有实际意义了。
这两天刚好看到llamaindex的创始人Jerry Liu分享了一个用llama3做100%本地化RAG的教程,是lightningai的工程师Akshay刚出的。
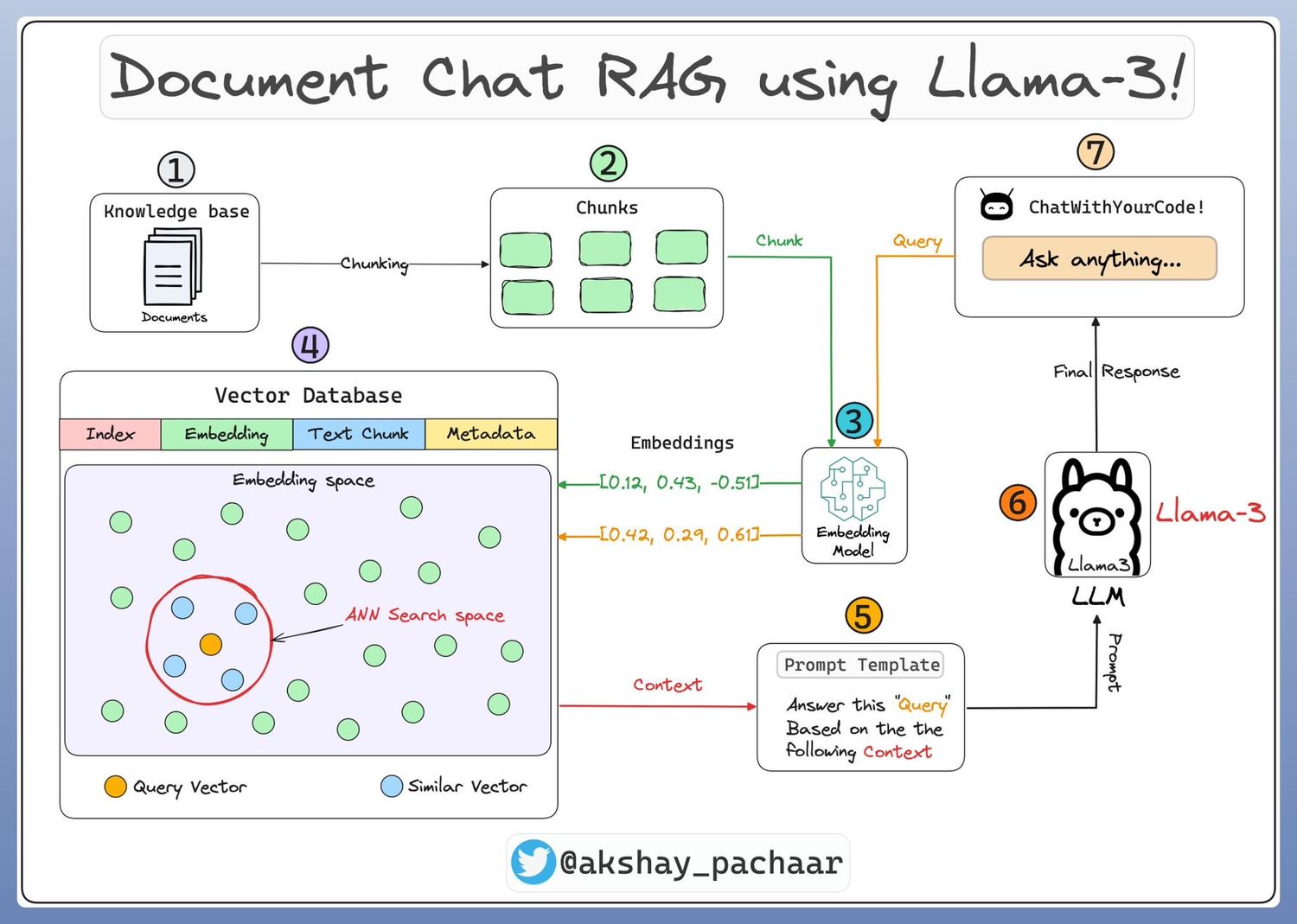
核心流程如下:
Step 1 & 2: 加载知识库
教程示意了如何把作为知识库的文档加载到llamaindex。
Step 3: embedding模型
下一步,用embedding模型生成文档的切块chunks和user queries的向量化表达,教程里用的embedding模型是Snowflake的`arctic-embed-m`。
Step 4: 索引和存储
生成的向量化表达embeddings存储在一个向量存储中,并通过在数据上创建索引以实现快速retrieval和相似性检索。llamaindex提供了一个默认的内存中的向量存储,可供快速实验。
Step 5: 自定义prompt模板
在prompt里带入query和检索后得到的context两个变量即可。
Step 6 & 7: 设置query引擎
在上一步基础上,把query和context带入LLM。
Step 8: 创建聊天界面UI
教程中以streamlit为例创建了chat的UI。
最后,小哥也非常贴心地附上了所有的代码并宣传了教程使用的运行环境,也就是他自家产品lightningai,链接在这里➡️ lightning.ai (不知道是不是这两天白嫖的人太多了,现在注册账户都要审核一会😂)
llamaindex创始人转发教程链接➡️ x.com
之前大家总讨论为什么在中国企业级的大语言模型应用似乎没怎么实现落地和普及,核心原因之一就是开源模型的能力与gpt4之间巨大的差异。
而llama3的出现,让100%本地化RAG更有实际意义了。
这两天刚好看到llamaindex的创始人Jerry Liu分享了一个用llama3做100%本地化RAG的教程,是lightningai的工程师Akshay刚出的。
核心流程如下:
Step 1 & 2: 加载知识库
教程示意了如何把作为知识库的文档加载到llamaindex。
Step 3: embedding模型
下一步,用embedding模型生成文档的切块chunks和user queries的向量化表达,教程里用的embedding模型是Snowflake的`arctic-embed-m`。
Step 4: 索引和存储
生成的向量化表达embeddings存储在一个向量存储中,并通过在数据上创建索引以实现快速retrieval和相似性检索。llamaindex提供了一个默认的内存中的向量存储,可供快速实验。
Step 5: 自定义prompt模板
在prompt里带入query和检索后得到的context两个变量即可。
Step 6 & 7: 设置query引擎
在上一步基础上,把query和context带入LLM。
Step 8: 创建聊天界面UI
教程中以streamlit为例创建了chat的UI。
最后,小哥也非常贴心地附上了所有的代码并宣传了教程使用的运行环境,也就是他自家产品lightningai,链接在这里➡️ lightning.ai (不知道是不是这两天白嫖的人太多了,现在注册账户都要审核一会😂)
llamaindex创始人转发教程链接➡️ x.com
42 741
来自圈子

AI探索站
77711人已经加入