即刻App年轻人的同好社区
下载
斯坦福这节课讲清楚了LLM做RAG所有最重要的问题。
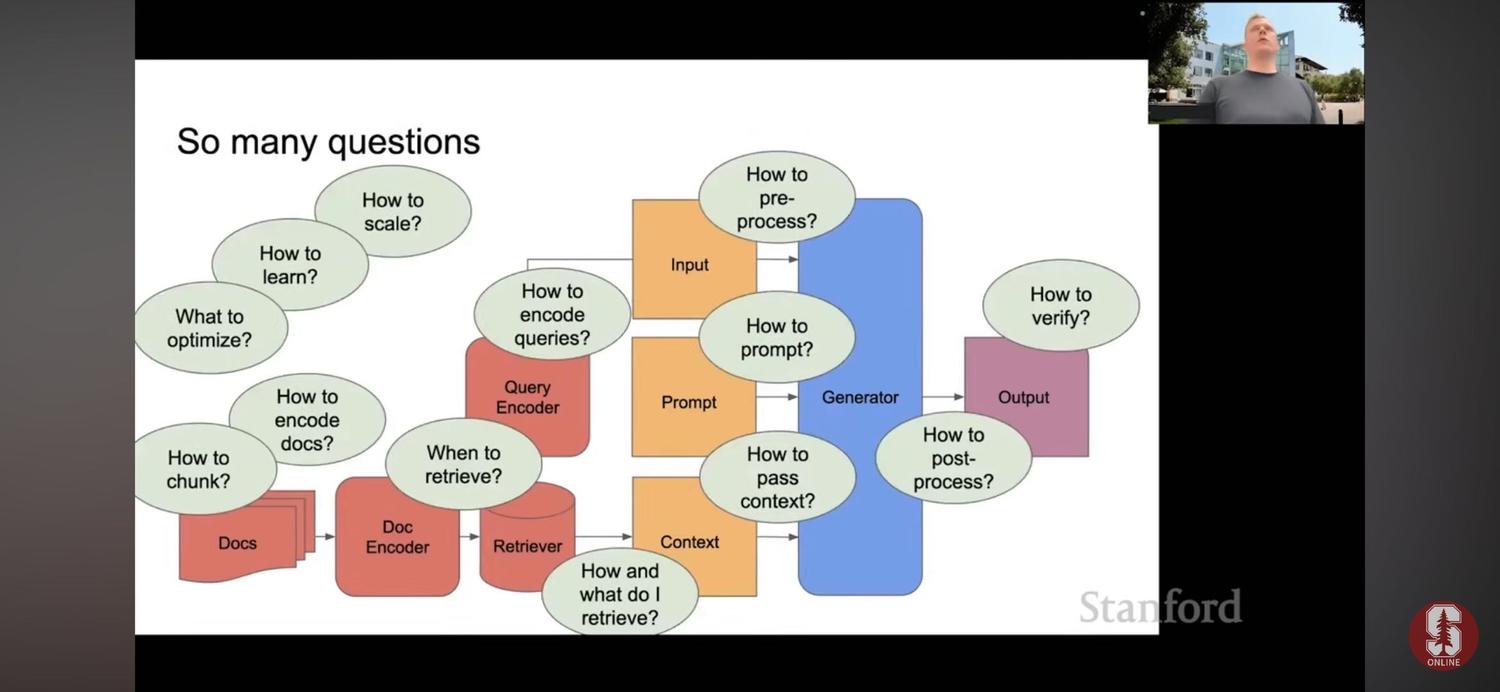
这节课就是传说中的Stanford CS25中的一节讲座<Retrieval Augmented Language Models>。授课人就是RAG论文的作者之一Douwe Kiela,课程中他分享了一个检索增强语言模型的架构图。
这张图重要到让我觉得,做RAG只要记住这一张图就够了。所有相关概念和工程实践中的权衡,全都涵盖在这张图的架构和问题中了。
这个架构主要包括input、prompt、通过retriever检索增强生成的context,然后把这三部分一起输入给generator即模型,最终输出output作为结果。
❇️❇️关于这几个核心概念,值得注意的是:
1️⃣input和prompt的区别和联系在于,input可理解为既包含system prompt,又包含用户输入的检索范围的指向,而prompt则强调用户输入的指令。
🌟以公司知识库RAG举例,比如用户输入chatbot的内容为"检索公司2023年的财务数据并生成总结报告",其中"公司2023年的财务数据"是对公司知识库检索范围的指向,应理解为input的一部分,而"检索并生成总结报告"则是指令,应理解为prompt。
2️⃣retriever的作用机制,我理解类似于在图书馆借书的过程,提供书名(query)-系统查找图书编号(query编码)-对应书架书籍编号(docs编码)-找到并借出图书(context)。
🌟接着上文公司知识库的例子,从input获取query(如"2023年资产负债表, 2023年利润表, 2023年现金流量表"),对应的query编码("2023年资产负债表, 2023年利润表, 2023年现金流量表"的向量化表达)在docs编码(公司知识库所有文本的向量化表达)中检索匹配,提取匹配的部分作为context(涉及公司2023年财务数据的文本)。
🌟其中query和input的关系,我想到两种可能性,一种是直接把input作为query,另一种是模型基于input生成的query,架构图简化表达了。
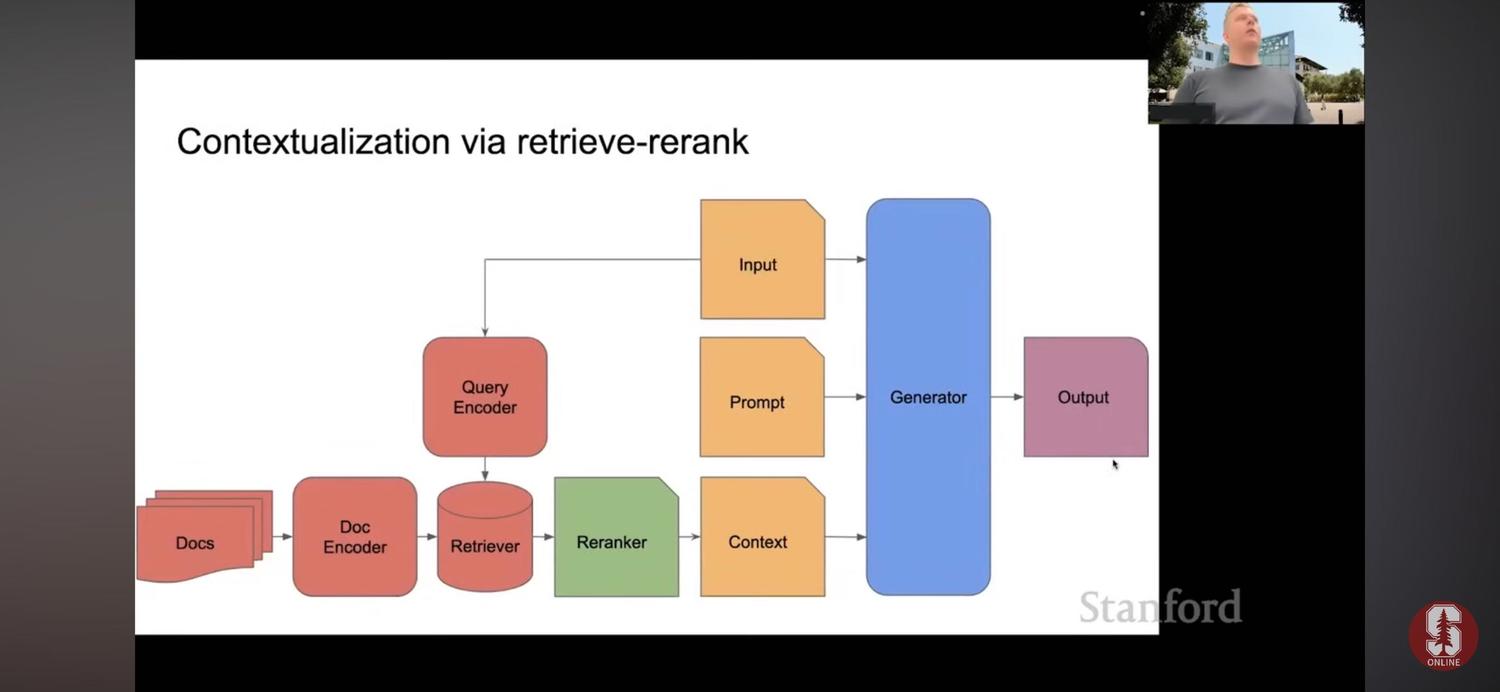
3️⃣retriever和context之间可加一步reranker架构,对检索结果按特定规则进行重新排序。reranking的机制既可通过模型判断,也可在模型基础上预设特定规则。
🌟比如根据员工职级限制其可获取的企业知识库信息范围。
❇️❇️目前工程实践上,大家把优化的重点基本都放在了retrieve环节里,这里面涉及三个重要的问题:
1️⃣how and what do I retrieve:从传统的相似性检索、文本检索,到目前最常用的依托于embedding的语义检索,大家在实践中仍在不断迭代。Kiela后面也提到有研究希望把整个retriever过程做成一个模型,他也在课程中构想未来应该把retriever的训练也纳入到LLM的训练架构中。
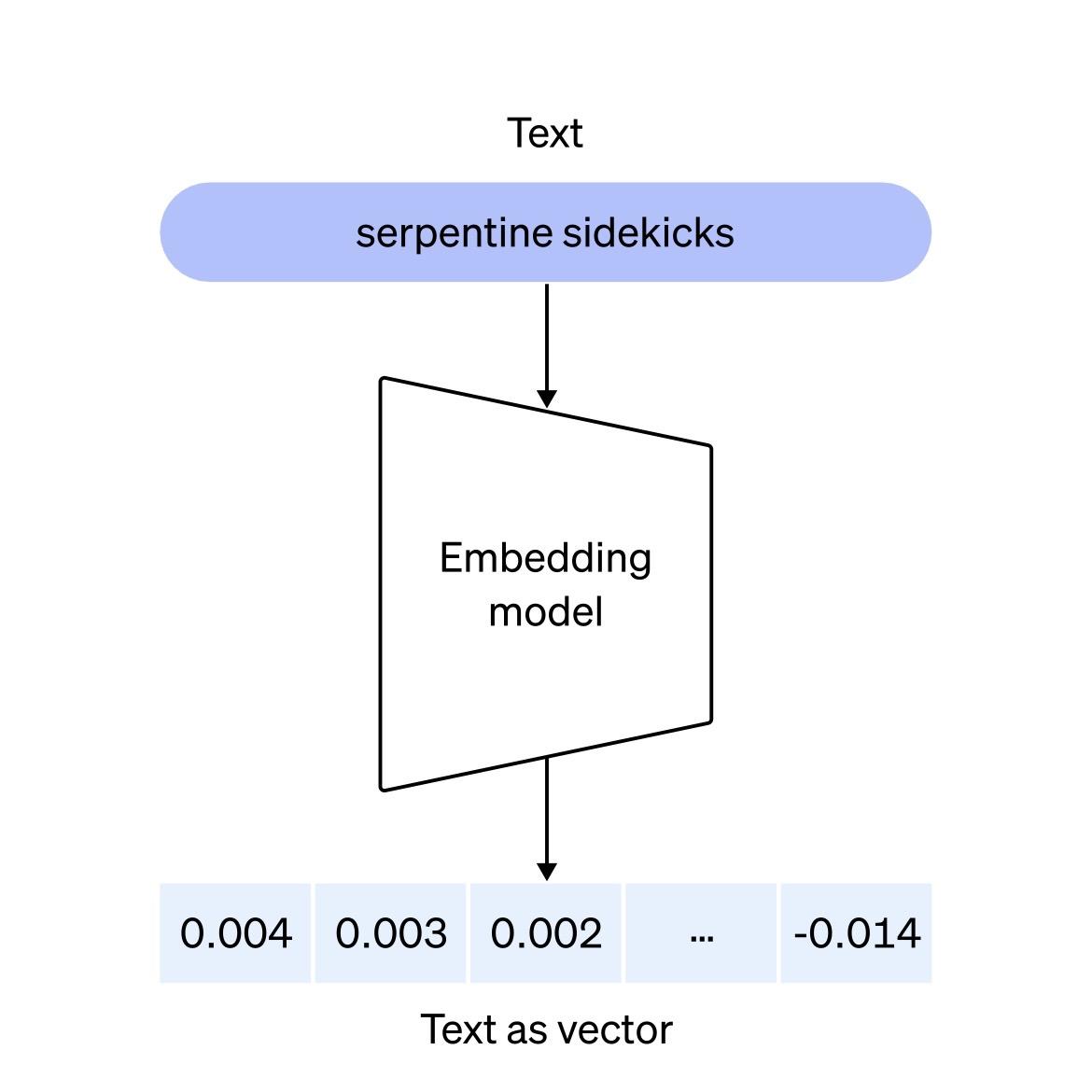
🌟文本的embedding可简化理解为文本的向量化表达,并且可根据不同文本的向量化表达,判断出文本之间语义的远近亲疏关系。
🌟目前的文本emebedding也都是通过模型来实现的,这类模型也在不断迭代。OpenAI在今年1月份推出了text-embedding-3(small和large两版),相比其2022年12月推出的ada-002模型,在性能上获得了显著提升。
🌟用于多语言检索的常用基准(MIRACL)平均分数已从 31.4%(ada-002)增加到 44.0%(3-small)和54.9%(3-large)。
🌟附图之一是OpenAI对其text emebedding模型作用机制的示意。
2️⃣When to retrieve: 一般就两种思路。一种是在获得检索范围后即retrieve,另一种是让模型判断何时retrieve。
3️⃣How to encode: 如何编码也直接影响了如何检索的过程。
❇️❇️其他问题:
1️⃣how to pre-process: 实际上强调就是input要包含system prompt,可设定角色、技能、任务、工作流、限制条件等。
2️⃣how to prompt: 涉及提示词工程的方法论。
3️⃣how to pass context: 可以把context作为prompt的一部分以文本形式输入,也可通过代码的方式代入。
4️⃣how to post-process: 比如格式化输出的处理,如固定输出json格式,或固定在末尾输出reference列表等。
5️⃣how to verify: 指的是如何验证output的效果或质量,比如验证output与知识库的相关性、准确性等。
❇️❇️最后,还有关于RAG整体架构的审视框架:
1️⃣How to optimize: 各环节哪些地方可以优化。架构中已经列出的问题都是思考的重点。
2️⃣How to learn: 这里的learn应该指的是机器学习的learn,探讨各环节从software 1.0的静态架构向机器学习和software 2.0的演进。
3️⃣how to scale: 如何应对规模化的问题。
🌟比如关于知识库如何chunk、何时编码,在知识库过大时就不适合提前预处理好chunk和编码。或者大量用户同时prompt该如何应对。
❇️❇️前段时间判断过2024年会是RAG应用爆发的一年m.okjike.com,自己在2B业务中也涉及RAG工程的落地,所以花了些精力来学习这节课。以上内容夹杂了不少自己的个人理解,欢迎批评指正,一起交流学习~
❇️❇️links:
🌟Stanford CS25 V4 2024春季课程(面向公众开放,有人想一起学习搭子么?) web.stanford.edu
🌟Stanford CS25 V3: Retrieval Augmented Language Models www.youtube.com
🌟RAG论文原文<Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks> arxiv.org
🌟OpenAI text-embedding-3 models openai.com
🌟OpenAI text-embedding-ada-002 model openai.com
🌟Software 2.0 by Andrej Karpathy karpathy.medium.com
🌟 Kiela在讲这节课几个月后在其创立的Contextual AI正式推出RAG 2.0 contextual.ai
这节课就是传说中的Stanford CS25中的一节讲座<Retrieval Augmented Language Models>。授课人就是RAG论文的作者之一Douwe Kiela,课程中他分享了一个检索增强语言模型的架构图。
这张图重要到让我觉得,做RAG只要记住这一张图就够了。所有相关概念和工程实践中的权衡,全都涵盖在这张图的架构和问题中了。
这个架构主要包括input、prompt、通过retriever检索增强生成的context,然后把这三部分一起输入给generator即模型,最终输出output作为结果。
❇️❇️关于这几个核心概念,值得注意的是:
1️⃣input和prompt的区别和联系在于,input可理解为既包含system prompt,又包含用户输入的检索范围的指向,而prompt则强调用户输入的指令。
🌟以公司知识库RAG举例,比如用户输入chatbot的内容为"检索公司2023年的财务数据并生成总结报告",其中"公司2023年的财务数据"是对公司知识库检索范围的指向,应理解为input的一部分,而"检索并生成总结报告"则是指令,应理解为prompt。
2️⃣retriever的作用机制,我理解类似于在图书馆借书的过程,提供书名(query)-系统查找图书编号(query编码)-对应书架书籍编号(docs编码)-找到并借出图书(context)。
🌟接着上文公司知识库的例子,从input获取query(如"2023年资产负债表, 2023年利润表, 2023年现金流量表"),对应的query编码("2023年资产负债表, 2023年利润表, 2023年现金流量表"的向量化表达)在docs编码(公司知识库所有文本的向量化表达)中检索匹配,提取匹配的部分作为context(涉及公司2023年财务数据的文本)。
🌟其中query和input的关系,我想到两种可能性,一种是直接把input作为query,另一种是模型基于input生成的query,架构图简化表达了。
3️⃣retriever和context之间可加一步reranker架构,对检索结果按特定规则进行重新排序。reranking的机制既可通过模型判断,也可在模型基础上预设特定规则。
🌟比如根据员工职级限制其可获取的企业知识库信息范围。
❇️❇️目前工程实践上,大家把优化的重点基本都放在了retrieve环节里,这里面涉及三个重要的问题:
1️⃣how and what do I retrieve:从传统的相似性检索、文本检索,到目前最常用的依托于embedding的语义检索,大家在实践中仍在不断迭代。Kiela后面也提到有研究希望把整个retriever过程做成一个模型,他也在课程中构想未来应该把retriever的训练也纳入到LLM的训练架构中。
🌟文本的embedding可简化理解为文本的向量化表达,并且可根据不同文本的向量化表达,判断出文本之间语义的远近亲疏关系。
🌟目前的文本emebedding也都是通过模型来实现的,这类模型也在不断迭代。OpenAI在今年1月份推出了text-embedding-3(small和large两版),相比其2022年12月推出的ada-002模型,在性能上获得了显著提升。
🌟用于多语言检索的常用基准(MIRACL)平均分数已从 31.4%(ada-002)增加到 44.0%(3-small)和54.9%(3-large)。
🌟附图之一是OpenAI对其text emebedding模型作用机制的示意。
2️⃣When to retrieve: 一般就两种思路。一种是在获得检索范围后即retrieve,另一种是让模型判断何时retrieve。
3️⃣How to encode: 如何编码也直接影响了如何检索的过程。
❇️❇️其他问题:
1️⃣how to pre-process: 实际上强调就是input要包含system prompt,可设定角色、技能、任务、工作流、限制条件等。
2️⃣how to prompt: 涉及提示词工程的方法论。
3️⃣how to pass context: 可以把context作为prompt的一部分以文本形式输入,也可通过代码的方式代入。
4️⃣how to post-process: 比如格式化输出的处理,如固定输出json格式,或固定在末尾输出reference列表等。
5️⃣how to verify: 指的是如何验证output的效果或质量,比如验证output与知识库的相关性、准确性等。
❇️❇️最后,还有关于RAG整体架构的审视框架:
1️⃣How to optimize: 各环节哪些地方可以优化。架构中已经列出的问题都是思考的重点。
2️⃣How to learn: 这里的learn应该指的是机器学习的learn,探讨各环节从software 1.0的静态架构向机器学习和software 2.0的演进。
3️⃣how to scale: 如何应对规模化的问题。
🌟比如关于知识库如何chunk、何时编码,在知识库过大时就不适合提前预处理好chunk和编码。或者大量用户同时prompt该如何应对。
❇️❇️前段时间判断过2024年会是RAG应用爆发的一年m.okjike.com,自己在2B业务中也涉及RAG工程的落地,所以花了些精力来学习这节课。以上内容夹杂了不少自己的个人理解,欢迎批评指正,一起交流学习~
❇️❇️links:
🌟Stanford CS25 V4 2024春季课程(面向公众开放,有人想一起学习搭子么?) web.stanford.edu
🌟Stanford CS25 V3: Retrieval Augmented Language Models www.youtube.com
🌟RAG论文原文<Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks> arxiv.org
🌟OpenAI text-embedding-3 models openai.com
🌟OpenAI text-embedding-ada-002 model openai.com
🌟Software 2.0 by Andrej Karpathy karpathy.medium.com
🌟 Kiela在讲这节课几个月后在其创立的Contextual AI正式推出RAG 2.0 contextual.ai

154 22134
来自圈子

AI探索站
114132人已经加入