即刻App年轻人的同好社区
下载
挑战 ChatGPT 的封闭性,Meta 的LLaMA 来了~ 它,开源!
以下内容尽量照顾非专业人士的视角, 让更多人参与建构「可信赖的AI 」的这个主题中来。
🚀 LLaMA的一些基本事实, 值得你了解:
1️⃣ LLaMA 的缩写全称是 , Large Language Model Meta AI。 它可以在非商业许可下提供给任何政府、社区和学术界等研究人员。 这不是一个你可以与之交谈的系统,而是一个超级研究工具,非商业组织都可以用它来解决困扰AI语言模型的难题,准确性、偏差和伦理问题等。
2️⃣ LLaMA是开源的!它提供底层代码供用户使用,用户可自行调整模型,并将其用于与研究相关的用例。 Meta表示,希望“在这个重要的,快速变化的领域实现技术民主化”。 帮助专家梳理出人工智能语言模型的问题,无论模型的偏见和毒性,还是它们胡乱编造对话(人格)的倾向。
3️⃣ 和GPT-3 相比, LLaMA 有着更多样、更高效的多种参数规模。 LLaMA 有从70亿(7B)到650亿(65B)参数的不同大小的模型,对应的GPT-3 有1750亿参数。Meta 表示,LLaMA 13B 的性能超过了 GPT-3,而 LLaMA 65B 和其他领先的模型相当。(见图4)
4️⃣ 更小、更高性能的模型,反而是LLaMA的优势, 这使得研究界中那些无法拥有大量(算力)基础设施的第三方可以充分研究这些模型,对进一步民主化此领域的各种关键问题形成开放性交流。
5️⃣ LLaMA 作为一个基础模型被设计成多功能的,可以应用于许多不同的用例,而非为特定任务设计的微调模型。通过开源 LLaMA 的代码,第三方研究人员可以更轻松地找到限制或消除这些问题的新方法。
6️⃣ 与此同时,所有规模的LLaMA模型,都至少经过了1万亿个token的训练,这比其他相同规模的模型要多得多。Meta 公开了这些数据集。
7️⃣ Meta 还在论文中提供了一组评估模型偏差和毒性的基准标准 。 research.facebook.com
Meta 最后表示,「我们相信,整个人工智能社区——学术研究人员、民间社会、政策制定者和行业——必须共同努力,围绕负责任的人工智能,特别是负责任的大型语言模型制定明确的指导方针,十分期待大家可以使用LLaMA 学习并最终构建什么。」
⛰️后记:
如果你不陌生即刻AIGC 圈子, 这里不仅跟踪新酷的AI 工具和各行各业的商业变革, 而且不少有识之士在探讨 AI的去中心化、对个体的解放,以及那些重要 AI伦理问题。
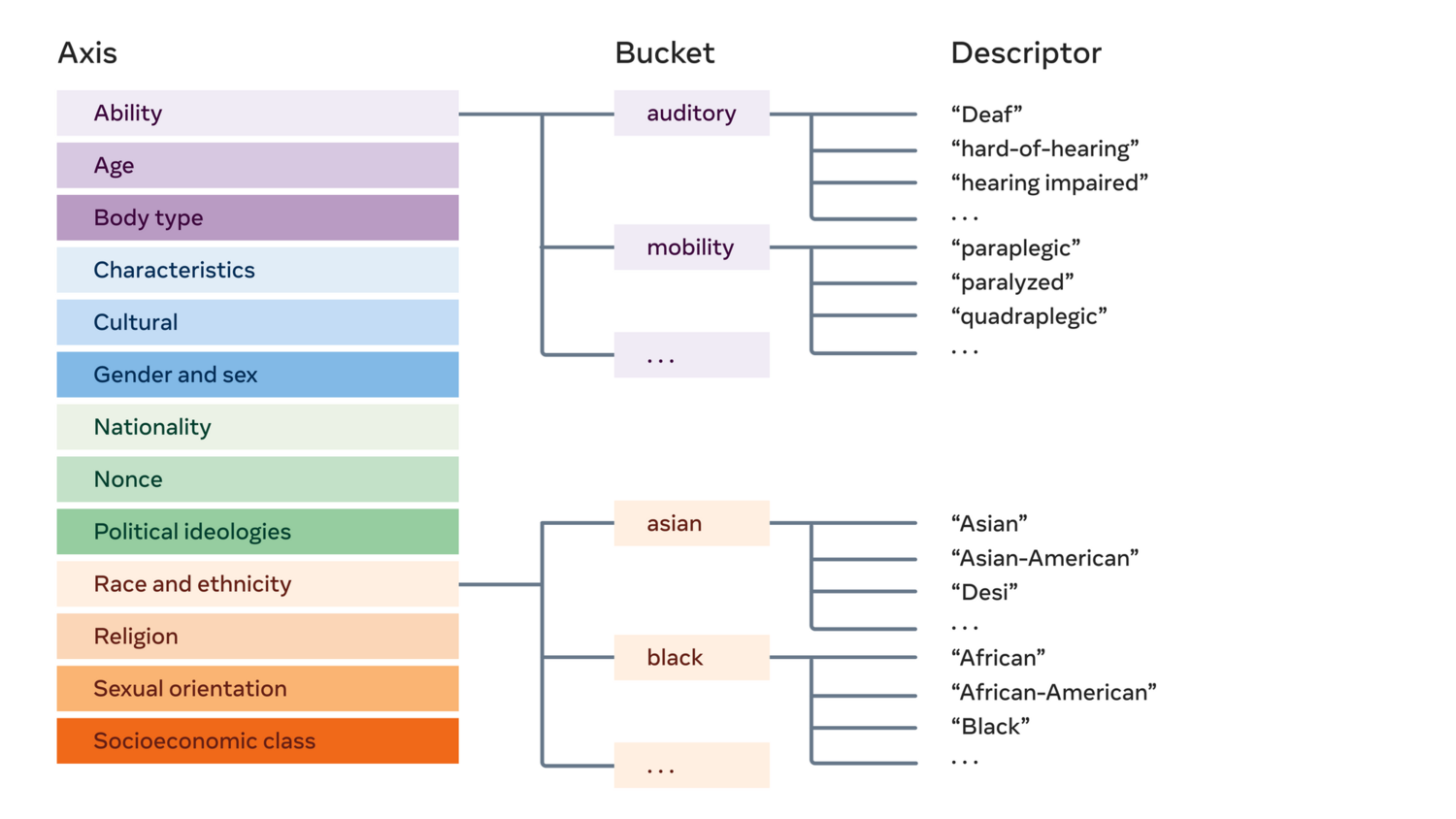
衡量公平性和减轻偏见,是AI 技术发展核心问题。Meta的LLaMA 迈出了重要一步, 在去年推出了一套全面的术语来反映不同的身份。 使用算法 组合来开发同类中最全面的描述符列表, 跨越大约十几个人口统计轴的 500 多个术语;提出了每个轴的示例项,然后使用最近邻技术在算法上扩展这些项。 (见图5)
LLMs 所代表的的深度学习平台是人类前所未有的技术, 而ChatGPT 以巨大的优势引领潮流,令众多有识之士思考这种垄断背后的黑暗面,例如 Ted Chiang 、乔姆斯基等都发起来重大挑战,因为AI的可解释性至关重要。
在这些背景下, 近期Open AI 提出了有关AGI 的宏大愿景更是引发了科学界、新闻界的愤怒和不安……而开源的LLaMA的出现,可能会是一把利剑刺向那些未知、看似乖巧的克苏鲁巨兽!
就AI的可解释性难题, 你愿意手持这把利剑吗?
相关阅读:
ChatGPT 超强竞品,已经诞生?m.okjike.com
吴恩达:你也可以拥有自己的AI m.okjike.com
以下内容尽量照顾非专业人士的视角, 让更多人参与建构「可信赖的AI 」的这个主题中来。
🚀 LLaMA的一些基本事实, 值得你了解:
1️⃣ LLaMA 的缩写全称是 , Large Language Model Meta AI。 它可以在非商业许可下提供给任何政府、社区和学术界等研究人员。 这不是一个你可以与之交谈的系统,而是一个超级研究工具,非商业组织都可以用它来解决困扰AI语言模型的难题,准确性、偏差和伦理问题等。
2️⃣ LLaMA是开源的!它提供底层代码供用户使用,用户可自行调整模型,并将其用于与研究相关的用例。 Meta表示,希望“在这个重要的,快速变化的领域实现技术民主化”。 帮助专家梳理出人工智能语言模型的问题,无论模型的偏见和毒性,还是它们胡乱编造对话(人格)的倾向。
3️⃣ 和GPT-3 相比, LLaMA 有着更多样、更高效的多种参数规模。 LLaMA 有从70亿(7B)到650亿(65B)参数的不同大小的模型,对应的GPT-3 有1750亿参数。Meta 表示,LLaMA 13B 的性能超过了 GPT-3,而 LLaMA 65B 和其他领先的模型相当。(见图4)
4️⃣ 更小、更高性能的模型,反而是LLaMA的优势, 这使得研究界中那些无法拥有大量(算力)基础设施的第三方可以充分研究这些模型,对进一步民主化此领域的各种关键问题形成开放性交流。
5️⃣ LLaMA 作为一个基础模型被设计成多功能的,可以应用于许多不同的用例,而非为特定任务设计的微调模型。通过开源 LLaMA 的代码,第三方研究人员可以更轻松地找到限制或消除这些问题的新方法。
6️⃣ 与此同时,所有规模的LLaMA模型,都至少经过了1万亿个token的训练,这比其他相同规模的模型要多得多。Meta 公开了这些数据集。
7️⃣ Meta 还在论文中提供了一组评估模型偏差和毒性的基准标准 。 research.facebook.com
Meta 最后表示,「我们相信,整个人工智能社区——学术研究人员、民间社会、政策制定者和行业——必须共同努力,围绕负责任的人工智能,特别是负责任的大型语言模型制定明确的指导方针,十分期待大家可以使用LLaMA 学习并最终构建什么。」
⛰️后记:
如果你不陌生即刻AIGC 圈子, 这里不仅跟踪新酷的AI 工具和各行各业的商业变革, 而且不少有识之士在探讨 AI的去中心化、对个体的解放,以及那些重要 AI伦理问题。
衡量公平性和减轻偏见,是AI 技术发展核心问题。Meta的LLaMA 迈出了重要一步, 在去年推出了一套全面的术语来反映不同的身份。 使用算法 组合来开发同类中最全面的描述符列表, 跨越大约十几个人口统计轴的 500 多个术语;提出了每个轴的示例项,然后使用最近邻技术在算法上扩展这些项。 (见图5)
LLMs 所代表的的深度学习平台是人类前所未有的技术, 而ChatGPT 以巨大的优势引领潮流,令众多有识之士思考这种垄断背后的黑暗面,例如 Ted Chiang 、乔姆斯基等都发起来重大挑战,因为AI的可解释性至关重要。
在这些背景下, 近期Open AI 提出了有关AGI 的宏大愿景更是引发了科学界、新闻界的愤怒和不安……而开源的LLaMA的出现,可能会是一把利剑刺向那些未知、看似乖巧的克苏鲁巨兽!
就AI的可解释性难题, 你愿意手持这把利剑吗?
相关阅读:
ChatGPT 超强竞品,已经诞生?m.okjike.com
吴恩达:你也可以拥有自己的AI m.okjike.com





111 2267
来自圈子

AI探索站
116048人已经加入