即刻App年轻人的同好社区
下载


0 00
比普通人省50%!ZA Bank 拼团 Lv2 攻略! ZA Bank 的美... 电子银行说实话比实体央行方便,也更适合年轻人。还可以投资🐈
比普通人省50%!ZA Bank 拼团 Lv2 攻略! - 小红书
0 00
link.metamask.io
metamask最新版有空投活动,有兴趣的可以参加下
metamask最新版有空投活动,有兴趣的可以参加下
2 00
focuse 一个月激活码!
FocuSee Invite Compaign
0 00
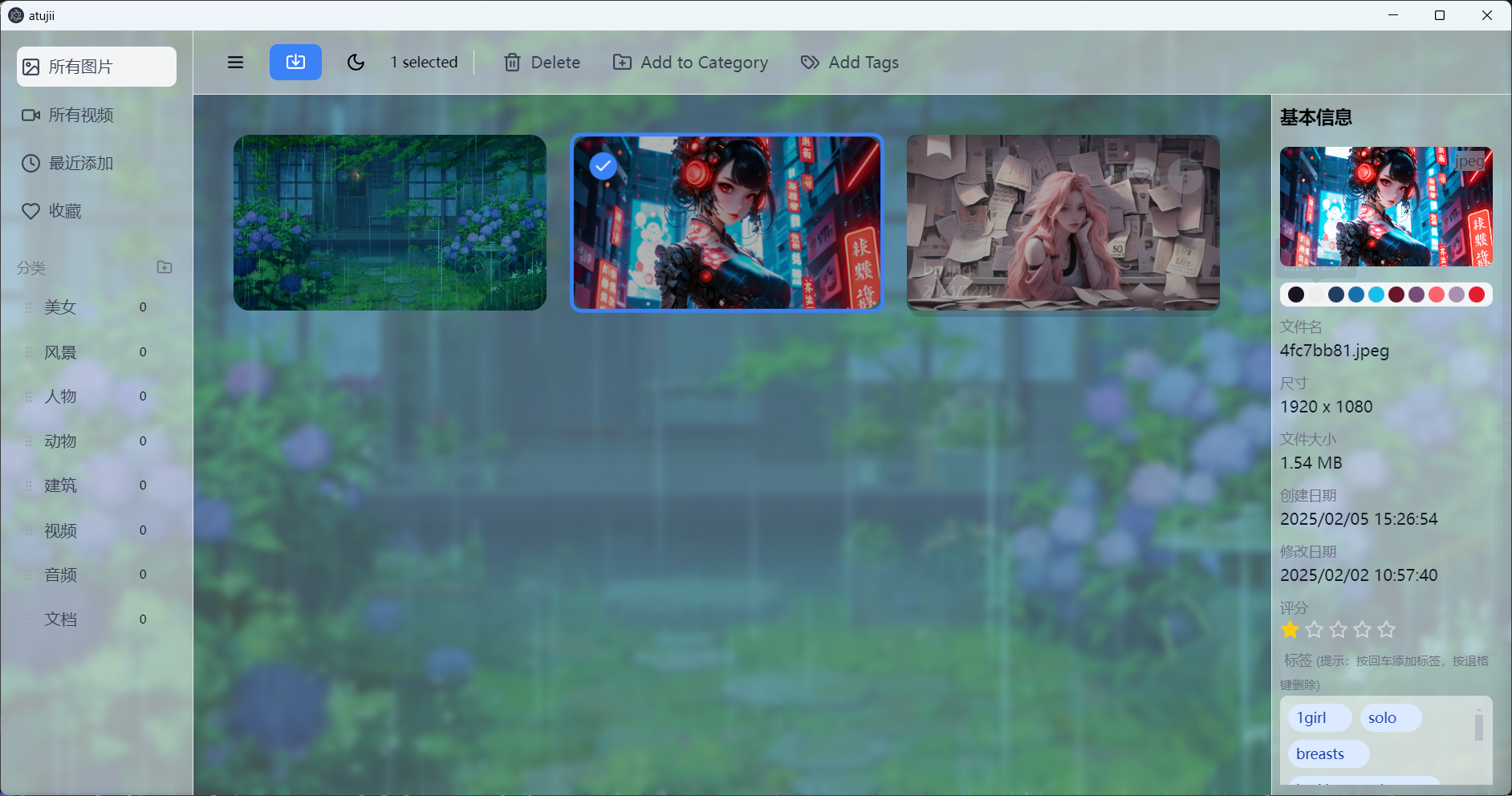
分享一个我做的图片资源管理工具!

《王炸!》atujii 功能重大更新!---- 功能简介_哔哩哔哩_bilibili
0 01
OpenAI于2025年3月26日发布了GPT-4o图像生成器,这是其最新一代多模态模型GPT-4o的重要功能升级,标志着OpenAI在图像生成领域的重大突破。以下是关于GPT-4o图像生成器的详细介绍:
- **精确文本渲染**:能够准确地在图像中嵌入文字,解决了以往AI模型在可读性和文本布局方面的困难,可创建标志、菜单、邀请函和信息图表等。
- **上下文连贯性**:利用聊天历史,允许用户交互式地完善图像,并在多次生成中保持连贯性,确保角色等元素在多次迭代中保持一致性。
- **多样化风格适应**:可以生成或转换图像为各种风格,从手绘草图到高分辨率照片写实风格,满足不同场景和用户的需求。
- **非自回归生成技术**:采用非自回归生成技术,直接生成整个图像,不再依赖于逐像素的生成过程,生成速度更快,图像质量更高。
### 应用场景
- **设计与品牌**:生成带有精确文本布局的标志、海报和广告,帮助设计师快速实现创意构思。
- **教育与可视化**:创建科学图表、信息图表和历史图像用于学习,将抽象的知识以直观的图像形式呈现,提高教学效果。
- **营销与内容创作**:根据品牌需求制作社交媒体素材、活动邀请函和数字插图,提升内容创作的效率和质量。
### 价格与订阅政策
- **价格降低**:与GPT-4 Turbo相比,GPT-4o的价格降低了50%,成本恰好是10倍GPT-3.5。具体为5美元/百万输入token和15美元/百万输出token。
- **免费用户开放**:这是OpenAI首次直接向非付费客户提供“最佳”模型,免费用户也可以使用GPT-4o的图像生成功能,不过可能会有一些使用限制。
### 优势与创新
- **原生集成**:与以往的图像生成模型(如DALL-E)不同,GPT-4o的图像生成器是其多模态模型的一部分,训练整个模型同时理解文本、图像等多种媒体形式,实现了更自然的多模态融合。
- **性能提升**:相比之前的模型,GPT-4o在多个方面进行了改进,如更好的文本集成、增强的上下文理解、改进的多对象绑定等,能够处理更复杂的场景和指令。
- **多轮交互优化**:支持多轮对话的图像生成,用户可以在聊天中逐步完善图像,模型能够根据上下文信息生成更符合用户需求的图像。
### 局限性与挑战
- **裁剪问题**:大尺寸图像(如海报)有时可能会裁剪过紧。
- **非拉丁文字的准确性**:某些非英语字符可能无法正确渲染。
- **小文本的细节保留**:高度详细或小字体的文本可能会失去清晰度。
图片太多管理不了?可以试试我写的管理软件。
- **精确文本渲染**:能够准确地在图像中嵌入文字,解决了以往AI模型在可读性和文本布局方面的困难,可创建标志、菜单、邀请函和信息图表等。
- **上下文连贯性**:利用聊天历史,允许用户交互式地完善图像,并在多次生成中保持连贯性,确保角色等元素在多次迭代中保持一致性。
- **多样化风格适应**:可以生成或转换图像为各种风格,从手绘草图到高分辨率照片写实风格,满足不同场景和用户的需求。
- **非自回归生成技术**:采用非自回归生成技术,直接生成整个图像,不再依赖于逐像素的生成过程,生成速度更快,图像质量更高。
### 应用场景
- **设计与品牌**:生成带有精确文本布局的标志、海报和广告,帮助设计师快速实现创意构思。
- **教育与可视化**:创建科学图表、信息图表和历史图像用于学习,将抽象的知识以直观的图像形式呈现,提高教学效果。
- **营销与内容创作**:根据品牌需求制作社交媒体素材、活动邀请函和数字插图,提升内容创作的效率和质量。
### 价格与订阅政策
- **价格降低**:与GPT-4 Turbo相比,GPT-4o的价格降低了50%,成本恰好是10倍GPT-3.5。具体为5美元/百万输入token和15美元/百万输出token。
- **免费用户开放**:这是OpenAI首次直接向非付费客户提供“最佳”模型,免费用户也可以使用GPT-4o的图像生成功能,不过可能会有一些使用限制。
### 优势与创新
- **原生集成**:与以往的图像生成模型(如DALL-E)不同,GPT-4o的图像生成器是其多模态模型的一部分,训练整个模型同时理解文本、图像等多种媒体形式,实现了更自然的多模态融合。
- **性能提升**:相比之前的模型,GPT-4o在多个方面进行了改进,如更好的文本集成、增强的上下文理解、改进的多对象绑定等,能够处理更复杂的场景和指令。
- **多轮交互优化**:支持多轮对话的图像生成,用户可以在聊天中逐步完善图像,模型能够根据上下文信息生成更符合用户需求的图像。
### 局限性与挑战
- **裁剪问题**:大尺寸图像(如海报)有时可能会裁剪过紧。
- **非拉丁文字的准确性**:某些非英语字符可能无法正确渲染。
- **小文本的细节保留**:高度详细或小字体的文本可能会失去清晰度。
图片太多管理不了?可以试试我写的管理软件。
Release v0.4.2 · xingBaGan/atujii
1 00
做了个atujii软件功能介绍短片。开发也有一个月时间了。
【开源图片管理器】《atujii》 你的 《eagle》平替,将一直开源免费!_哔哩哔哩_bilibili
2 30
github.com
业余时间开发图片管理软件,终于在三个端编译过了。马上能发版了!
业余时间开发图片管理软件,终于在三个端编译过了。马上能发版了!
图迹 - 优雅的本地图片管理工具
3 70
ai生图太多图片,管理不过来。最近写了个工具,大家有这个需求吗?
GitHub - xingBaGan/atujii: ai 图片管理工具
2 00
x.com 本地使用 bolt.new, 好玩!
2 00