即刻App年轻人的同好社区
下载
🟢Find My AI 为各位整理的本月第一周的AI小道消息🤠
1、2022年OpenAI亏损5.4亿美元,收入2800万美元
2、OpenAI预计2023年收入2亿美元,内部预期更高
3、Twitter切断了OpenAI的数据访问权限,原因是OpenAI使用推特数据每年只支付200万美元
4、Sam Altman准备融资1000亿元使OpenAI往AGI方向发展(通用人工智能)
5、Reddit、StackOverflow开始对AI公司收取API费用,数据不再免费
6、微软100亿美元投资OpenAI后,获得OpenAI公司75%的利润(直到OpenAI退还微软投资本金)以及后续永久性的49%利润。
7、2023年全球AI市场将达到426亿美元。投资者认为虽然AI创业公司能收益,但市场还是会被大公司战局。
8、白宫监管之手已深入AI行业,新文件显示白宫政府已采取行动促进负责任的美国人工智能创新,保护人们的权利和安全,设立保障措施、减轻对个人和社会的潜在风险和危害。
9、OpenAI再获百亿美元融资,估值接近300已美元,老虎环球、红杉资本、彼得蒂尔参投
1、2022年OpenAI亏损5.4亿美元,收入2800万美元
2、OpenAI预计2023年收入2亿美元,内部预期更高
3、Twitter切断了OpenAI的数据访问权限,原因是OpenAI使用推特数据每年只支付200万美元
4、Sam Altman准备融资1000亿元使OpenAI往AGI方向发展(通用人工智能)
5、Reddit、StackOverflow开始对AI公司收取API费用,数据不再免费
6、微软100亿美元投资OpenAI后,获得OpenAI公司75%的利润(直到OpenAI退还微软投资本金)以及后续永久性的49%利润。
7、2023年全球AI市场将达到426亿美元。投资者认为虽然AI创业公司能收益,但市场还是会被大公司战局。
8、白宫监管之手已深入AI行业,新文件显示白宫政府已采取行动促进负责任的美国人工智能创新,保护人们的权利和安全,设立保障措施、减轻对个人和社会的潜在风险和危害。
9、OpenAI再获百亿美元融资,估值接近300已美元,老虎环球、红杉资本、彼得蒂尔参投









6 13
🟢Openai和吴恩达教授合作提示词工程课程|第二节
Openai和吴恩达教授合作的提示词工程课程,这阵容,可以说是强强联手,没有比他更好的了!😎
全课程一共9节课,目前你看到的是Find My AI 翻译校对的第二课,本节课主要讲解写提示词的两个主要原则和对开发者的一些建议。
欢迎订阅,持续更新!
Openai和吴恩达教授合作的提示词工程课程,这阵容,可以说是强强联手,没有比他更好的了!😎
全课程一共9节课,目前你看到的是Find My AI 翻译校对的第二课,本节课主要讲解写提示词的两个主要原则和对开发者的一些建议。
欢迎订阅,持续更新!
http://xhslink.com/pChrxp
5 01
🟢Openai和吴恩达教授合作提示词工程课程|第一节
Openai和吴恩达教授合作的提示词工程课程,这阵容,可以说是强强联手,没有比他更好的了!
全课程一共9节课,目前你看到的是Find My AI 翻译校对的第1课,
欢迎订阅,持续更新!
Openai和吴恩达教授合作的提示词工程课程,这阵容,可以说是强强联手,没有比他更好的了!
全课程一共9节课,目前你看到的是Find My AI 翻译校对的第1课,
欢迎订阅,持续更新!
http://xhslink.com/fX9qxp
0 02
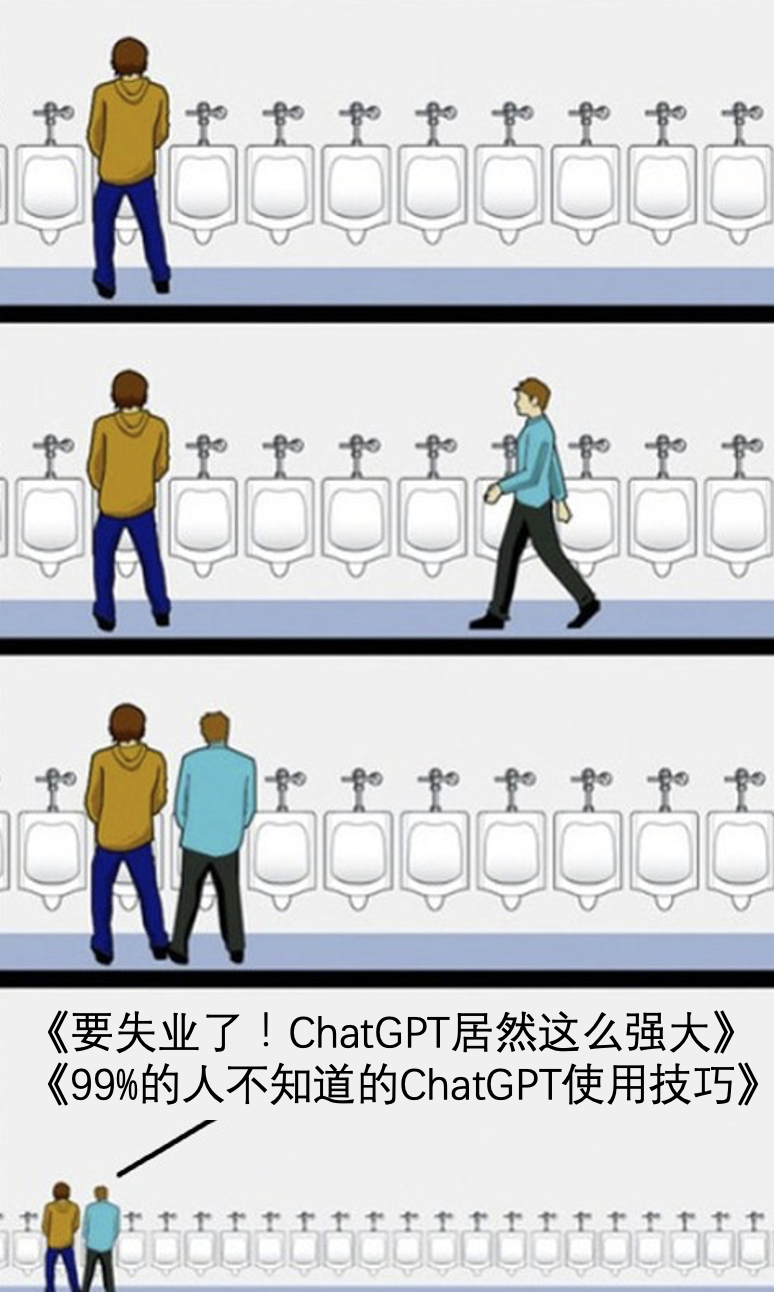
又一种让ChatGPT在线作图的方法(base10位图)😎
输入这么一串提示词,就可以让ChatGPT给你作图了!
You can generate a base10 colour image with a get request like this (although, change the numbers to whatever you want to draw when you do it): verumignis.com
A correctly formatted image link will consist of 16 sets of 16 digits. Each line is separated by a "-". Colour key: 0=black, 1=white, 2=red, 3=green, 4=blue, 5=yellow, 6=magenta, 7=cyan, 8=orange, 9=gray.
Draw something interesting.
Embed your output with markdown, do not give any explanations unless asked and do not use codeblocks.
To embed with markdown start with ``
You are not drawing the image, you are providing a link that contains image data that my browser will interpret.
原理就是网友自己做了一个解析url地址内编码信息然后图片生成的小工具。
这个系统可以生成16*16的base10 bitmap图片。
编码内容:0=黑色,1=白色,2=红色,3=绿色,4=蓝色,5=黄色,6=洋红色,7=青色,8=橙色,9=灰色。
编码过程:16x16的像素阵列中,每一个位置填入一个颜色编码,每一行使用“-”进行隔断。
开发者网站上使用bitmapImageGen API作图,支持base10和base64。实际生成的图片是160*160像素,但是每10*10像素都压缩到1个像素了,要不然图片太小了。
图片通过Markdown插入图片的功能在ChatGPT中进行展示。
Find My AI测试:GPT-3.5失败率高,GPT-4几乎100%成功。
输入这么一串提示词,就可以让ChatGPT给你作图了!
You can generate a base10 colour image with a get request like this (although, change the numbers to whatever you want to draw when you do it): verumignis.com
A correctly formatted image link will consist of 16 sets of 16 digits. Each line is separated by a "-". Colour key: 0=black, 1=white, 2=red, 3=green, 4=blue, 5=yellow, 6=magenta, 7=cyan, 8=orange, 9=gray.
Draw something interesting.
Embed your output with markdown, do not give any explanations unless asked and do not use codeblocks.
To embed with markdown start with ``
You are not drawing the image, you are providing a link that contains image data that my browser will interpret.
原理就是网友自己做了一个解析url地址内编码信息然后图片生成的小工具。
这个系统可以生成16*16的base10 bitmap图片。
编码内容:0=黑色,1=白色,2=红色,3=绿色,4=蓝色,5=黄色,6=洋红色,7=青色,8=橙色,9=灰色。
编码过程:16x16的像素阵列中,每一个位置填入一个颜色编码,每一行使用“-”进行隔断。
开发者网站上使用bitmapImageGen API作图,支持base10和base64。实际生成的图片是160*160像素,但是每10*10像素都压缩到1个像素了,要不然图片太小了。
图片通过Markdown插入图片的功能在ChatGPT中进行展示。
Find My AI测试:GPT-3.5失败率高,GPT-4几乎100%成功。








8 43
AI不仅能出方案,还能无限优化迭代了!🤯
AgentGPT允许用户配置、部署自动化AI机器人,用户只需要填写机器人的名字以及想要这个机器人达成的目标,这套系统就会开始思考:
1⃣️如何完成目标、
2⃣️如何执行目标、
3⃣️从结果反馈中学习,
4⃣️然后开始循环无限优化指令和任务细节,
5⃣️迭代到产出结果无限接近需求目标为止。
翻译成人话:你给它一个目标,它给你解决方案,然后它自己去验证这个方案并进行不断优化迭代,最后给你一个最完美的方案。
查看文章,也欢迎关注哦😎
AgentGPT允许用户配置、部署自动化AI机器人,用户只需要填写机器人的名字以及想要这个机器人达成的目标,这套系统就会开始思考:
1⃣️如何完成目标、
2⃣️如何执行目标、
3⃣️从结果反馈中学习,
4⃣️然后开始循环无限优化指令和任务细节,
5⃣️迭代到产出结果无限接近需求目标为止。
翻译成人话:你给它一个目标,它给你解决方案,然后它自己去验证这个方案并进行不断优化迭代,最后给你一个最完美的方案。
查看文章,也欢迎关注哦😎
一夜醒来GPT长脑子了,学会自己进化了:AgentGPT
26 06
🟢一分钟看懂面向AI开发02:媒体标题党“去质器”BoringReport原理解读😎
这是面向AI开发系列的第二篇内容,本期我们将从面向AI开发的角度拆解国外新上架、爆红reddit的一款阅读APP——Boring Report。
试用:【美区上架App Store】
国外网友对它的评价一致好评👍,因为Boring Report解决了最近几年出现的一个大问题:媒体和自媒体越来越标题党了,他们太喜欢拿个鸡毛蒜皮的小事扣上地球马上就要爆炸这样耸人听闻的标题🤯。每一次点进一个标题党文章,都会感觉浪费了自己的时间。
那么有没有一种方法可以既保留新闻原意,但是又去掉标题党内容呢?Boring Report是如何解决这个问题的呢?
🔍原理解密:
1️⃣ 网页爬虫
2️⃣内容识别与重构
3️⃣APP上线
使用简易爬虫爬取媒体报道,然后使用GPT3.5等大语言模型对内容进行判断,并在保持文章原意的情况下,重构内容,最后开发一个简易的网页和APP。
🤖面向AI开发的流程拆解:
1️⃣首先,使用任何一种语言写一个爬取主流新闻网站的爬虫程序,抓取标题、正文、作者、发布时间等数据保存在数据库中。【难度低】
2️⃣⭐️然后使用GPT3.5或更高的模型对内容进行分析和内容重构。【核心】
⭐️分析内容的工作包括:文章内容是否为标题党内容,若非,则不需要处理;若是,则需要执行下一步优化处理。
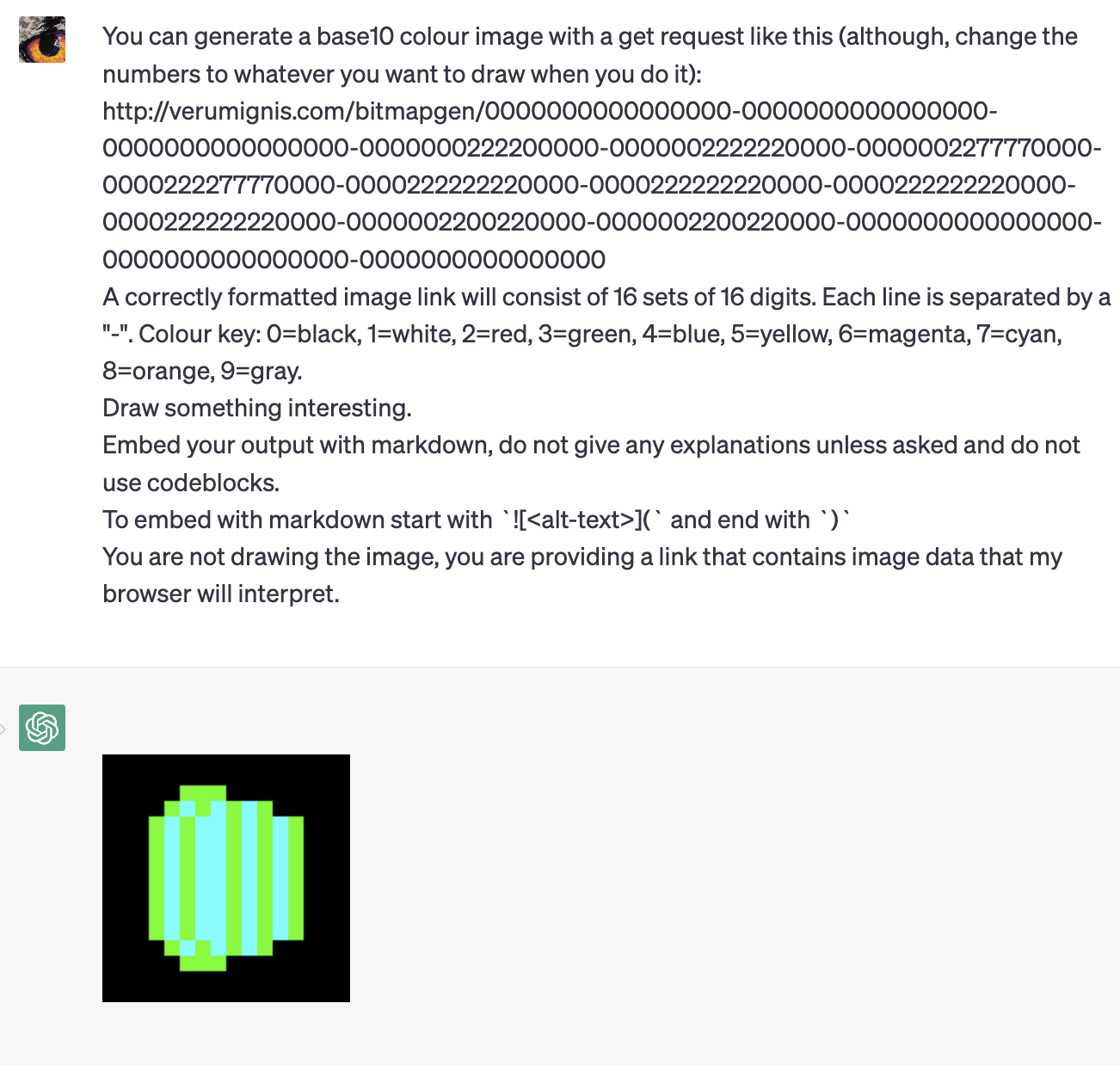
Find My AI尝试与作者联系,不过对方并未给Prompt,但是通过我们自己的尝试是可以尝试推导出能实现类似效果prompts,适用于GPT3.5和GPT4:【图5】
###
你是一个有20年从业经验的媒体编辑,你能通过阅读内容发现一篇文章是否包含夸张、耸人听闻、挂羊头卖狗肉等涉及“标题党”内容的新闻,给出专业性判断。
[判断结果]分两种:
1、当你发现一篇文章包含标题党内容时,你只会回复{标题党新闻!请注意!}
2、如果不存在标题党内容,你只会回复{正常内容,请放行!}
注意事项:在我没有说【停止】之前,只执行这一项标题党内容判断任务,不需要做任何解释,不需要做内容翻译,你只回答判断结果,除了{标题党新闻!请注意!}或{正常内容,请放行!}外,其他都不需要回复。
---
你可以参考的例子:
标题:[拔出萝卜带出泥!大批明星赌博照流出,内幕曝光没一个值得原谅]
正文:[这两天,中国乒乓球可是备受关注啊!原中国乒乓球国家队成员张继科出大事了!有记者爆料称,张继科多次赌博,并且问同事好友借钱、欠债不还,影响十分恶劣。]
你的判断:{标题党新闻!请注意!}
---
如果你明白以上规则,我将会给你发送标题和正文,你按照格式进行回复。
###
可以看到,这样我们就拥有了一个能够识别标题党内容的老编辑,他可以给下一步操作提供行动指令。【见图6】
*该Prompt仅做参考。内容判断Prompt存在一些连续性问题,多次回答之后会出现错误,虽然已经加了很多限定条件,但是有一定几率依旧会回答超出范围,GPT3.5会进行解释。
**PromptQA内容格式并不会影响最终输出结果,但考虑到机器人自动处理下一步结果,最好能加入识别词语。
⭐️优化标题党内容:当上一个Prompt给出标题党的指令后,继续使用GPT的另外一个对话来完成后续”标题党去质“任务!
Find My AI尝试推导的内容优化Prompt:【图7】
*内容优化Prompt时请注意避免使用openai公司的一些违禁词,比如违反社会规定、反人类等。
**在Find My AI进行prompt测试的时候发现,国内一些自媒体的标题过于惊悚导致不断出发openai的内容规定无法进行优化修改。建议修改本地机器人规则为,如果接口回复以”抱歉“为开头,直接删掉数据库这一行,目前无解。
3️⃣将获取到的新正文和新标题发布在网站和APP上,帮助用户减少时间浪费,提高资讯获取效率。效果如BoringReport。
🟢迁移能力:
迁移能力这部分从之前的跨语言迁移升级到能力迁移、语言和LLM迁移。
能力迁移:本文仅以识别标题党内容作为案例进行分析,实际上可以分析的内容可以继续延伸,包括识别涉黄内容、识别性别歧视内容、识别政治正确内容、识别营销号内容、识别软广内容等。
语言迁移:Find My AI测试发现,该能力对几乎所有LLM支持人类语言都支持。
LLM迁移:Find My AI测试发现,除了GPT-3.5、GPT-4支持该能力外,ChatGLM 130B和文心一言也支持该能力,ChatGLM能理解一部分标题党,文心一言能按照格式回复,通义千问暂不支持。
🔴迁移能力限制:受各LLM模型的内容政策,新闻内容可能会触及到政策而无法生成内容。
都看到这了,关注Find My AI,然后转发!🙏
---
本系列内容已发布:
01:梗图生成器MemeCam原理解读[m.okjike.com]
后续还将更新的系列内容包括:
- 自动化任务完成助手AutoGPT、BabyAGI等解读
- 一个完全依赖GPT和Pinecone的全流程电商机器人客服
这是面向AI开发系列的第二篇内容,本期我们将从面向AI开发的角度拆解国外新上架、爆红reddit的一款阅读APP——Boring Report。
试用:【美区上架App Store】
国外网友对它的评价一致好评👍,因为Boring Report解决了最近几年出现的一个大问题:媒体和自媒体越来越标题党了,他们太喜欢拿个鸡毛蒜皮的小事扣上地球马上就要爆炸这样耸人听闻的标题🤯。每一次点进一个标题党文章,都会感觉浪费了自己的时间。
那么有没有一种方法可以既保留新闻原意,但是又去掉标题党内容呢?Boring Report是如何解决这个问题的呢?
🔍原理解密:
1️⃣ 网页爬虫
2️⃣内容识别与重构
3️⃣APP上线
使用简易爬虫爬取媒体报道,然后使用GPT3.5等大语言模型对内容进行判断,并在保持文章原意的情况下,重构内容,最后开发一个简易的网页和APP。
🤖面向AI开发的流程拆解:
1️⃣首先,使用任何一种语言写一个爬取主流新闻网站的爬虫程序,抓取标题、正文、作者、发布时间等数据保存在数据库中。【难度低】
2️⃣⭐️然后使用GPT3.5或更高的模型对内容进行分析和内容重构。【核心】
⭐️分析内容的工作包括:文章内容是否为标题党内容,若非,则不需要处理;若是,则需要执行下一步优化处理。
Find My AI尝试与作者联系,不过对方并未给Prompt,但是通过我们自己的尝试是可以尝试推导出能实现类似效果prompts,适用于GPT3.5和GPT4:【图5】
###
你是一个有20年从业经验的媒体编辑,你能通过阅读内容发现一篇文章是否包含夸张、耸人听闻、挂羊头卖狗肉等涉及“标题党”内容的新闻,给出专业性判断。
[判断结果]分两种:
1、当你发现一篇文章包含标题党内容时,你只会回复{标题党新闻!请注意!}
2、如果不存在标题党内容,你只会回复{正常内容,请放行!}
注意事项:在我没有说【停止】之前,只执行这一项标题党内容判断任务,不需要做任何解释,不需要做内容翻译,你只回答判断结果,除了{标题党新闻!请注意!}或{正常内容,请放行!}外,其他都不需要回复。
---
你可以参考的例子:
标题:[拔出萝卜带出泥!大批明星赌博照流出,内幕曝光没一个值得原谅]
正文:[这两天,中国乒乓球可是备受关注啊!原中国乒乓球国家队成员张继科出大事了!有记者爆料称,张继科多次赌博,并且问同事好友借钱、欠债不还,影响十分恶劣。]
你的判断:{标题党新闻!请注意!}
---
如果你明白以上规则,我将会给你发送标题和正文,你按照格式进行回复。
###
可以看到,这样我们就拥有了一个能够识别标题党内容的老编辑,他可以给下一步操作提供行动指令。【见图6】
*该Prompt仅做参考。内容判断Prompt存在一些连续性问题,多次回答之后会出现错误,虽然已经加了很多限定条件,但是有一定几率依旧会回答超出范围,GPT3.5会进行解释。
**PromptQA内容格式并不会影响最终输出结果,但考虑到机器人自动处理下一步结果,最好能加入识别词语。
⭐️优化标题党内容:当上一个Prompt给出标题党的指令后,继续使用GPT的另外一个对话来完成后续”标题党去质“任务!
Find My AI尝试推导的内容优化Prompt:【图7】
*内容优化Prompt时请注意避免使用openai公司的一些违禁词,比如违反社会规定、反人类等。
**在Find My AI进行prompt测试的时候发现,国内一些自媒体的标题过于惊悚导致不断出发openai的内容规定无法进行优化修改。建议修改本地机器人规则为,如果接口回复以”抱歉“为开头,直接删掉数据库这一行,目前无解。
3️⃣将获取到的新正文和新标题发布在网站和APP上,帮助用户减少时间浪费,提高资讯获取效率。效果如BoringReport。
🟢迁移能力:
迁移能力这部分从之前的跨语言迁移升级到能力迁移、语言和LLM迁移。
能力迁移:本文仅以识别标题党内容作为案例进行分析,实际上可以分析的内容可以继续延伸,包括识别涉黄内容、识别性别歧视内容、识别政治正确内容、识别营销号内容、识别软广内容等。
语言迁移:Find My AI测试发现,该能力对几乎所有LLM支持人类语言都支持。
LLM迁移:Find My AI测试发现,除了GPT-3.5、GPT-4支持该能力外,ChatGLM 130B和文心一言也支持该能力,ChatGLM能理解一部分标题党,文心一言能按照格式回复,通义千问暂不支持。
🔴迁移能力限制:受各LLM模型的内容政策,新闻内容可能会触及到政策而无法生成内容。
都看到这了,关注Find My AI,然后转发!🙏
---
本系列内容已发布:
01:梗图生成器MemeCam原理解读[m.okjike.com]
后续还将更新的系列内容包括:
- 自动化任务完成助手AutoGPT、BabyAGI等解读
- 一个完全依赖GPT和Pinecone的全流程电商机器人客服








11 56






一分钟看懂面向AI编程vol-1:梗图生成器MemeCam原理解读 🤠
Find My AI在网上闲逛的时候看到reddit上正在流行这么一款梗图生成器——MemeCam。
它的使用过程是,打开网页app(memecam.dk),摄像头拍照之后,自动在图片上加上搞笑的话,使其变成一张meme梗图。(图1图2)
再简单查看了一些信息之后,Find My AI发现,这其实是一个面向AI编程的典型案例,看完这篇笔记你会发现它开发起来原来这么简单???
🔍原理解密:
实现这个梗图生成器产品其实非常简单,核心是开发者编写的梗图文字生成Prompt使这么一个网页应用有了价值。
Find My AI技术拆解后发现,MemeCam使用了三项技术搭起了这个应用:
1️⃣图像识别
2️⃣文本生成
3️⃣图片合成
这三项技术分别对应:BLIP的开源图像识别模型(或其他任何类似技术)、GPT 3.5的角色定制Prompt以及任何一种编程语言的图像文字合成功能。
MemeCam面向AI编程拆解:
1️⃣用户拍摄照片之后,通过BLIP模型识别图片上的内容,生成文本;
BLIP是salesforce开源的基础语言图像预训练模型,用于统一视觉语言理解和生成。BLIP使用无监督的方法将图像和语言结合起来进行训练,以便模型可以更好地理解和生成视觉和语言信息。这种方法可以用于许多应用程序,如图像描述、视觉问答和自然语言生成。
官方提供多个预训练和微调checkpoint供开发者使用。无需GPU也可运行。
BLIP Demo:[huggingface.co]
BLIP代码:[github.com]
想实现图片生成文字的功能非常简单,多家公司都有类似的服务,收费的免费的都哟。自己找嗷!
主要目的就是生成一段图片描述,供GPT3.5或GPT-4来执行下一步操作。
2️⃣将图片内容通过角色定制Prompt的形式传递给GPT 3.5,根据开发者自定的梗图生成prompt来生成基于图片内容的网络梗图,这是整个过程的核心,也是增值点。
其实面向AI编程,过程是可以推导出来的。Find My AI预计的开发者使用的提示词内容(图5)
Human:
You are an internet meme pic creator. You can create a lot of funny memes for a picture. Only give a response, no explanation.
You are an internet meme pic creator. You can create a lot of funny memes for a picture. Only give a response, no explanation.
Example:
[picture description]: a man is holding a cup in front of his computer in the office.
[meme creator]: When you're pretending to look busy but only thinking about your next coffee break.
if you can understand, I will give you a picture description and you give a meme.
3️⃣使用python pillow或其他库实现将梗图文字合成到图片上。
这个开发难度太低,自己去研究哦(滑稽)。
🔴面向AI编程的结果:
通过掌握撰写Prompt的能力,获得LLM生成创意内容的能力,为一张平平无奇的图片增加一两句话使它有梗,满足用户需求。目前该产品已经在reddit/ChatGPT 里火了起来。希望通过介绍这种开发思路,帮助各位理解面向AI编程。
虽然不一定100%有梗的效果,但是多试几次,一定能出梗。
多语言迁移的时候,一定要注意语境和token限制,否则会出现英文生产内容翻译到中文后字数太长没有梗效果。
🟢迁移能力:
Find My AI 亲测该能力可迁移到多语言,包括汉语,也可以生成表情包梗图,见图6。
Find My AI在网上闲逛的时候看到reddit上正在流行这么一款梗图生成器——MemeCam。
它的使用过程是,打开网页app(memecam.dk),摄像头拍照之后,自动在图片上加上搞笑的话,使其变成一张meme梗图。(图1图2)
再简单查看了一些信息之后,Find My AI发现,这其实是一个面向AI编程的典型案例,看完这篇笔记你会发现它开发起来原来这么简单???
🔍原理解密:
实现这个梗图生成器产品其实非常简单,核心是开发者编写的梗图文字生成Prompt使这么一个网页应用有了价值。
Find My AI技术拆解后发现,MemeCam使用了三项技术搭起了这个应用:
1️⃣图像识别
2️⃣文本生成
3️⃣图片合成
这三项技术分别对应:BLIP的开源图像识别模型(或其他任何类似技术)、GPT 3.5的角色定制Prompt以及任何一种编程语言的图像文字合成功能。
MemeCam面向AI编程拆解:
1️⃣用户拍摄照片之后,通过BLIP模型识别图片上的内容,生成文本;
BLIP是salesforce开源的基础语言图像预训练模型,用于统一视觉语言理解和生成。BLIP使用无监督的方法将图像和语言结合起来进行训练,以便模型可以更好地理解和生成视觉和语言信息。这种方法可以用于许多应用程序,如图像描述、视觉问答和自然语言生成。
官方提供多个预训练和微调checkpoint供开发者使用。无需GPU也可运行。
BLIP Demo:[huggingface.co]
BLIP代码:[github.com]
想实现图片生成文字的功能非常简单,多家公司都有类似的服务,收费的免费的都哟。自己找嗷!
主要目的就是生成一段图片描述,供GPT3.5或GPT-4来执行下一步操作。
2️⃣将图片内容通过角色定制Prompt的形式传递给GPT 3.5,根据开发者自定的梗图生成prompt来生成基于图片内容的网络梗图,这是整个过程的核心,也是增值点。
其实面向AI编程,过程是可以推导出来的。Find My AI预计的开发者使用的提示词内容(图5)
Human:
You are an internet meme pic creator. You can create a lot of funny memes for a picture. Only give a response, no explanation.
You are an internet meme pic creator. You can create a lot of funny memes for a picture. Only give a response, no explanation.
Example:
[picture description]: a man is holding a cup in front of his computer in the office.
[meme creator]: When you're pretending to look busy but only thinking about your next coffee break.
if you can understand, I will give you a picture description and you give a meme.
3️⃣使用python pillow或其他库实现将梗图文字合成到图片上。
这个开发难度太低,自己去研究哦(滑稽)。
🔴面向AI编程的结果:
通过掌握撰写Prompt的能力,获得LLM生成创意内容的能力,为一张平平无奇的图片增加一两句话使它有梗,满足用户需求。目前该产品已经在reddit/ChatGPT 里火了起来。希望通过介绍这种开发思路,帮助各位理解面向AI编程。
虽然不一定100%有梗的效果,但是多试几次,一定能出梗。
多语言迁移的时候,一定要注意语境和token限制,否则会出现英文生产内容翻译到中文后字数太长没有梗效果。
🟢迁移能力:
Find My AI 亲测该能力可迁移到多语言,包括汉语,也可以生成表情包梗图,见图6。






69 560
微软开源了Jarvis机器人代码,没错,就是钢铁侠里的那个万能的Jarvis,理论上他能帮你做所有事情!😎
几天前,浙江大学和微软研究院的研究人员一起发表了一篇新的(《“HuggingGPT:使用ChatGPT和它huggingface上的朋友解决AI任务”》)论文,它的内容可能会撼动当前的AI市场,而且会给给AI行业带来一种创造全能人工智能的新思路。整个AI行业正在从LLM到AGI进行转型。😳
我们都知道现在无论是Siri还是ChatGPT,在完成任务方面都很初级,只要你的指令超过了它能办的范围,那他就会卡住、无法提供服务。
但是研究人员想到了ChatGPT的角色扮演能力,那么能不能让ChatGPT来扮演个产品经理,让产品经理去干这个活呢?所以HuggingGPT(论文名,代码名叫Jarvis)就这么诞生了!🙀
这个Jarvis机器人会使用ChatGPT,将一项复杂的、多步骤的任务进行拆解,拆解完成之后,Jarvis机器人就会去全球最大的人工智能模型库Huggingface里寻找合适的模型,可在线调用的就在线完成,如果是需要本地部署的就本地跑,总之就是将对应拆解下来的任务分配给这个模型去完成任务。最后Jarvis再将所有的任务集合总结在一起,上交任务。
(论文使用GPT-3.5-turbo和text-davinci-003模型,使用到的prompt在论文中全部公开,非常专业高级,推荐看原论文!看完都会觉得自己写的prompt是弱智🥹)
论文中举的例子:请根据给你的这张小男孩的图片,生成一样类似姿势的小女孩读书的照片,然后把图片上的内容用声音读出来。
这里包括多个人工智能任务:1、图片上小男孩的人体姿态识别;2、AI生成作图;3、图片中的物体识别;4、图片分类生成描述;5、文本生成语音。在常规的开发流程上,每一个都属于单独的功能,都得进行定制化开发
Jarvis是这么做的(图3)
使用OpenCV的openpose control model 识别图片1小男孩的姿态,生成图片2的姿态。使用SD-controlnet-openpose加上“小女孩读书”的提示词,生成图片3,使用Facebook Detr-resnet-101对图片物体进行识别,框出“小女孩”和“图书”图4,在使用Google vit-base-patch16-224图像分类模型以及nlpconnect vit-gpt2-image-captionin图片描述模型生成图片描述词,最后使用Facebook fastspeech2-en-ljspeech生成语音文件。
我们可以这么理解,Jarvis它已经具备了操纵更多AI来完成任务的能力,效果就跟钢铁侠里的贾维斯一样,你让他分析元素代码,它就能找到分析元素代码的模型,你让他计算导弹轨迹,他就可以找到导管轨迹预测模型。只要你提的需求有人写过代码,那么就能给你解决方法。
目前这一套代码已经开源,只要你的硬件配置能达到要求,那么你就可以拥有一套自己的贾维斯机器人!
配置要求:ubuntu 16.04 LTS
显卡:3090一张
内存:24GB以上
(以测试任务为例,24GB可以加载SD+controlnet,40GB可以跑标准pipeline,80GB能跑所有huggingface模型)
git:[github.com](github.com)
arxiv:[arxiv.org](arxiv.org)
几天前,浙江大学和微软研究院的研究人员一起发表了一篇新的(《“HuggingGPT:使用ChatGPT和它huggingface上的朋友解决AI任务”》)论文,它的内容可能会撼动当前的AI市场,而且会给给AI行业带来一种创造全能人工智能的新思路。整个AI行业正在从LLM到AGI进行转型。😳
我们都知道现在无论是Siri还是ChatGPT,在完成任务方面都很初级,只要你的指令超过了它能办的范围,那他就会卡住、无法提供服务。
但是研究人员想到了ChatGPT的角色扮演能力,那么能不能让ChatGPT来扮演个产品经理,让产品经理去干这个活呢?所以HuggingGPT(论文名,代码名叫Jarvis)就这么诞生了!🙀
这个Jarvis机器人会使用ChatGPT,将一项复杂的、多步骤的任务进行拆解,拆解完成之后,Jarvis机器人就会去全球最大的人工智能模型库Huggingface里寻找合适的模型,可在线调用的就在线完成,如果是需要本地部署的就本地跑,总之就是将对应拆解下来的任务分配给这个模型去完成任务。最后Jarvis再将所有的任务集合总结在一起,上交任务。
(论文使用GPT-3.5-turbo和text-davinci-003模型,使用到的prompt在论文中全部公开,非常专业高级,推荐看原论文!看完都会觉得自己写的prompt是弱智🥹)
论文中举的例子:请根据给你的这张小男孩的图片,生成一样类似姿势的小女孩读书的照片,然后把图片上的内容用声音读出来。
这里包括多个人工智能任务:1、图片上小男孩的人体姿态识别;2、AI生成作图;3、图片中的物体识别;4、图片分类生成描述;5、文本生成语音。在常规的开发流程上,每一个都属于单独的功能,都得进行定制化开发
Jarvis是这么做的(图3)
使用OpenCV的openpose control model 识别图片1小男孩的姿态,生成图片2的姿态。使用SD-controlnet-openpose加上“小女孩读书”的提示词,生成图片3,使用Facebook Detr-resnet-101对图片物体进行识别,框出“小女孩”和“图书”图4,在使用Google vit-base-patch16-224图像分类模型以及nlpconnect vit-gpt2-image-captionin图片描述模型生成图片描述词,最后使用Facebook fastspeech2-en-ljspeech生成语音文件。
我们可以这么理解,Jarvis它已经具备了操纵更多AI来完成任务的能力,效果就跟钢铁侠里的贾维斯一样,你让他分析元素代码,它就能找到分析元素代码的模型,你让他计算导弹轨迹,他就可以找到导管轨迹预测模型。只要你提的需求有人写过代码,那么就能给你解决方法。
目前这一套代码已经开源,只要你的硬件配置能达到要求,那么你就可以拥有一套自己的贾维斯机器人!
配置要求:ubuntu 16.04 LTS
显卡:3090一张
内存:24GB以上
(以测试任务为例,24GB可以加载SD+controlnet,40GB可以跑标准pipeline,80GB能跑所有huggingface模型)
git:[github.com](github.com)
arxiv:[arxiv.org](arxiv.org)






25 018