即刻App年轻人的同好社区
下载
 置顶
置顶

这周我在 Databricks 发表了一篇技术博客,聊了聊我们是怎么提升企业级 AI 智能体性能的。有几个核心亮点可以分享:
📈 开源模型效果再进一步
我们采用自研的 GEPA 技术(由 Databricks 与 UC 伯克利联合开发),对 gpt-oss-120b 模型做了优化。在处理典型企业文档分析任务时,它的准确率超过了 Claude Opus 4.1 约 3%,而服务成本却只有后者的近百分之一。
🔁 方法通用性强,闭源模型也适用
我们将同样的 GEPA 应用于 Claude Sonnet 4 和 Opus 4.1,这些模型的表现也进一步提升,创造了新的记录。这说明 GEPA 在不同模型之间具备良好的可迁移性。
⚖️ 对比 SFT,GEPA 效果更好、成本更低
我们将 GEPA 与传统的监督微调做了对比:GEPA 不仅效果更优,服务成本也进一步降低 20%。而把两种方法结合使用时,效果更佳。
💸 全生命周期成本优势显著
我们还从实际部署的角度,估算了模型优化与推理的整体成本。GEPA + 开源模型方案在长期运行中成本显著更低。当业务请求量超过 10 万次之后,前期投入的优化成本被摊平到可以忽略不计。
基于这些实验结果,我们认为 GEPA + 开源模型是一个非常适合企业实际落地的技术组合。
写这篇文章的过程中,Databricks CTO Matei Zaharia 给了很多个关注,从他那里获得了很多中肯和有用的建议。文章发表之后,Matei 在社交媒体上帮忙大力推荐这篇文章,所以特别感谢 Matei!
欢迎阅读完整博客:www.databricks.com
📈 开源模型效果再进一步
我们采用自研的 GEPA 技术(由 Databricks 与 UC 伯克利联合开发),对 gpt-oss-120b 模型做了优化。在处理典型企业文档分析任务时,它的准确率超过了 Claude Opus 4.1 约 3%,而服务成本却只有后者的近百分之一。
🔁 方法通用性强,闭源模型也适用
我们将同样的 GEPA 应用于 Claude Sonnet 4 和 Opus 4.1,这些模型的表现也进一步提升,创造了新的记录。这说明 GEPA 在不同模型之间具备良好的可迁移性。
⚖️ 对比 SFT,GEPA 效果更好、成本更低
我们将 GEPA 与传统的监督微调做了对比:GEPA 不仅效果更优,服务成本也进一步降低 20%。而把两种方法结合使用时,效果更佳。
💸 全生命周期成本优势显著
我们还从实际部署的角度,估算了模型优化与推理的整体成本。GEPA + 开源模型方案在长期运行中成本显著更低。当业务请求量超过 10 万次之后,前期投入的优化成本被摊平到可以忽略不计。
基于这些实验结果,我们认为 GEPA + 开源模型是一个非常适合企业实际落地的技术组合。
写这篇文章的过程中,Databricks CTO Matei Zaharia 给了很多个关注,从他那里获得了很多中肯和有用的建议。文章发表之后,Matei 在社交媒体上帮忙大力推荐这篇文章,所以特别感谢 Matei!
欢迎阅读完整博客:www.databricks.com






14 14









我参与的开源大模型训练框架在Google Cloud Next大会上被展示在首位 🥳
Levanter 可以在TPU/GPU上训练大模型,易迁移、训练效率高,支持大规模的预训练和模型微调。
同在榜单上的Equinox也是非常好的library,轻量、易用、拓展性好。
Levanter 可以在TPU/GPU上训练大模型,易迁移、训练效率高,支持大规模的预训练和模型微调。
同在榜单上的Equinox也是非常好的library,轻量、易用、拓展性好。

33 30
Google 布局 TPU 开始于10年前,虽然当时的目的不是为了研发大模型,但依然可以说得上是目光长远,过程中的迭代和执行也做得到位。我有幸在18年接触过初代TPU,后来主要使用V3,最近开始用V5e,亲历了几代的发展进步。如今看到冰冻三尺,绝非一日之寒。
这不是一件轻易可以做到的事情。以Meta为例,几年前内部开始自研AI芯片,却也依然从Nvidia买了几十万张H100(不过Mark下单得早,时机上也显得很有远见)。短期来看,做基础大模型的公司的priority list里,降低算力成本应该不是排在首位的;即使是要降低算力成本,自研也绝非首选,还是有很多其他方式来达到目的,这一点上Mosaic ML和Anthropic都很有参考价值。
长期来看,一家公司垄断算力资源的怪象一定会被打破,算力的供给上会有更多的选择,infra上对于切换算力栈的支持也做会更好。也就是说,算力真正变得commoditized。而到那个时候,算力本身依然不会是大模型公司的首要问题,专有数据、应用场景、用户认知等等这些才会是护城河。
这不是一件轻易可以做到的事情。以Meta为例,几年前内部开始自研AI芯片,却也依然从Nvidia买了几十万张H100(不过Mark下单得早,时机上也显得很有远见)。短期来看,做基础大模型的公司的priority list里,降低算力成本应该不是排在首位的;即使是要降低算力成本,自研也绝非首选,还是有很多其他方式来达到目的,这一点上Mosaic ML和Anthropic都很有参考价值。
长期来看,一家公司垄断算力资源的怪象一定会被打破,算力的供给上会有更多的选择,infra上对于切换算力栈的支持也做会更好。也就是说,算力真正变得commoditized。而到那个时候,算力本身依然不会是大模型公司的首要问题,专有数据、应用场景、用户认知等等这些才会是护城河。

boyu_tian: 基座大模型的成功路径,究竟是买算力训模型,还是类似于Google布局TPU的方案,自研算力栈训模型呢?或许是一个简单的A+B-C的数学题 A:算力栈研发成本 B:公司切换算力栈的成本 C:在整个未来,比从英伟达买卡省的成本 大模型的特点使得所有不曾涉足infrastructure的公司开始有必要算这道题,而各家估算出的A,B,C,谁估算的更准,将成为可能的胜负手之一 (当然,除了基座大模型公司本身,也会有纯infra公司来挑战英伟达,最近我正在胡思乱想他们能否成功)
10 20




五个月前,当第一个 LLaMA 模型推出的时候,它刷新了人们的对于模型体积的预期:一个近似 GPT 能力的模型可以放到本地跑,65B 的模型也可以表现得很好。虽然 LLaMA 的开源限于学界,但是论文里详细介绍了制作方法,因此很多团队争相地复现数据和模型,开源界由此变得热闹,每周都有新的模型推出。
今天 LLaMA 2推出,显然开发团队从之前的成功中汲取了经验,强化了自己做对了的事,补上了没做的部分:预训练的数据加倍、上下文长度翻倍、按照RLHF微调出了chat版本、允许商业使用、在第一天就上了HuggingFace排行榜、推出了微调和部署的官方指南……不得不说这个团队开源做得的确是到位和专业。
不难想象 LLaMA 2 凭着自己的表现和 license 很有可能会成为未来一段时间学术界和工业界 LLM 项目的基石。想要从头开始预训练类似模型的团队会逐渐变少,依然坚持做的团队需要找到更独特的切入点/领域;相对应的,会有更多更多的团队会从 LLaMA 2开始计划和实施自己的项目,围绕 LLaMA 2 做微调、做部署、做服务的生态会越发繁荣。
今天 LLaMA 2推出,显然开发团队从之前的成功中汲取了经验,强化了自己做对了的事,补上了没做的部分:预训练的数据加倍、上下文长度翻倍、按照RLHF微调出了chat版本、允许商业使用、在第一天就上了HuggingFace排行榜、推出了微调和部署的官方指南……不得不说这个团队开源做得的确是到位和专业。
不难想象 LLaMA 2 凭着自己的表现和 license 很有可能会成为未来一段时间学术界和工业界 LLM 项目的基石。想要从头开始预训练类似模型的团队会逐渐变少,依然坚持做的团队需要找到更独特的切入点/领域;相对应的,会有更多更多的团队会从 LLaMA 2开始计划和实施自己的项目,围绕 LLaMA 2 做微调、做部署、做服务的生态会越发繁荣。
37 43
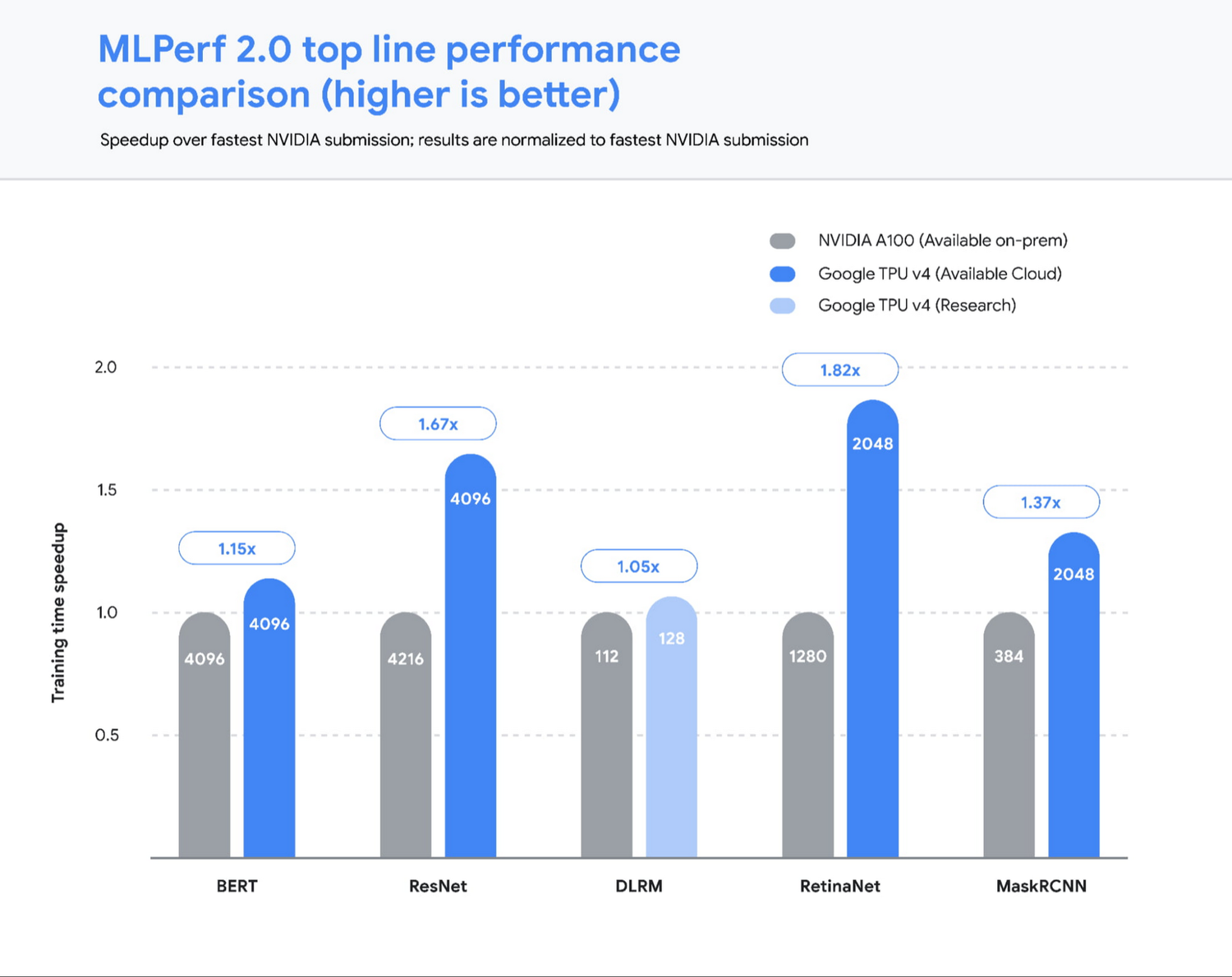
最近同时在使用 A100 和 TPU 做大规模训练,尝试了各自生态里的工具对于训练做了优化。TPU 的确是实打实非常好的训练硬件资源,速度快、吞吐量大、配套的分析和优化工具也到位。只可惜一直以来完全被 Google Cloud 和 TensorFlow 所绑定,跟外界的生态联系很少,和 PyTorch 以及 HuggingFace 基本绝缘,工具的易用性和文档也做得不够好。
如今 GPU 显卡短缺,推动了外界考虑使用 TPU 的动力,希望可以促使 TPU 能够更好地融入外界的机器学习生态。
如今 GPU 显卡短缺,推动了外界考虑使用 TPU 的动力,希望可以促使 TPU 能够更好地融入外界的机器学习生态。
21 00
最近因为一个契机,我从头开始参与基础大模型的训练开发。亲身经历去实践这个过程令我兴奋,也让我学到很多。有一些心得体会可以分享:
1. 人们常说GPT模型学习了整个互联网的数据,听上去只要能够把整个互联网爬下来就可以了,这个说法并不准确。训练的原始数据的确是来自互联网(CommonCrawl和私域的内容),但是实际拿来训练用的只是其中的子集——一个精心挑选的高质量子集。Sam Altman和Lex Fridman的访谈中说过,他们在数据上的大部分努力是去筛选信息,而不是堆积信息。原始数据需要经过大量的筛选、去重、格式化的处理,这个过程耗时耗力,也往往被忽视,但却是至关重要的。
2. 随着模型的参数上到百亿甚至千亿,很多新的能力开始涌现,而很多工程上的麻烦也随之而来。为了应对如此庞大的数据和模型体量,系统里几乎每个角落都需要优化,从数据处理、切分、训练时的样本和机器分布、梯度下降的稳定性、存储等等,各个方面都需要对应做提升,避免成为短板。一个成功的大模型背后离不开几十上百个细节的工程优化。
3. 一个还不成熟、有待考验的心得:现在想要做一个LLM,你并不需要一支庞大的团队。你只需要不到10个有经验、有行动力、能够高效合作的工程师就可以了。Meta、OpenAI、HuggingFace等团队都为这个生态提供了非常实用的轮子,只要使用得当,就可以获得明显的助力。当然,人数上可以精简,GPU计算资源还是得管够。
1. 人们常说GPT模型学习了整个互联网的数据,听上去只要能够把整个互联网爬下来就可以了,这个说法并不准确。训练的原始数据的确是来自互联网(CommonCrawl和私域的内容),但是实际拿来训练用的只是其中的子集——一个精心挑选的高质量子集。Sam Altman和Lex Fridman的访谈中说过,他们在数据上的大部分努力是去筛选信息,而不是堆积信息。原始数据需要经过大量的筛选、去重、格式化的处理,这个过程耗时耗力,也往往被忽视,但却是至关重要的。
2. 随着模型的参数上到百亿甚至千亿,很多新的能力开始涌现,而很多工程上的麻烦也随之而来。为了应对如此庞大的数据和模型体量,系统里几乎每个角落都需要优化,从数据处理、切分、训练时的样本和机器分布、梯度下降的稳定性、存储等等,各个方面都需要对应做提升,避免成为短板。一个成功的大模型背后离不开几十上百个细节的工程优化。
3. 一个还不成熟、有待考验的心得:现在想要做一个LLM,你并不需要一支庞大的团队。你只需要不到10个有经验、有行动力、能够高效合作的工程师就可以了。Meta、OpenAI、HuggingFace等团队都为这个生态提供了非常实用的轮子,只要使用得当,就可以获得明显的助力。当然,人数上可以精简,GPU计算资源还是得管够。

223 2361