即刻App年轻人的同好社区
下载
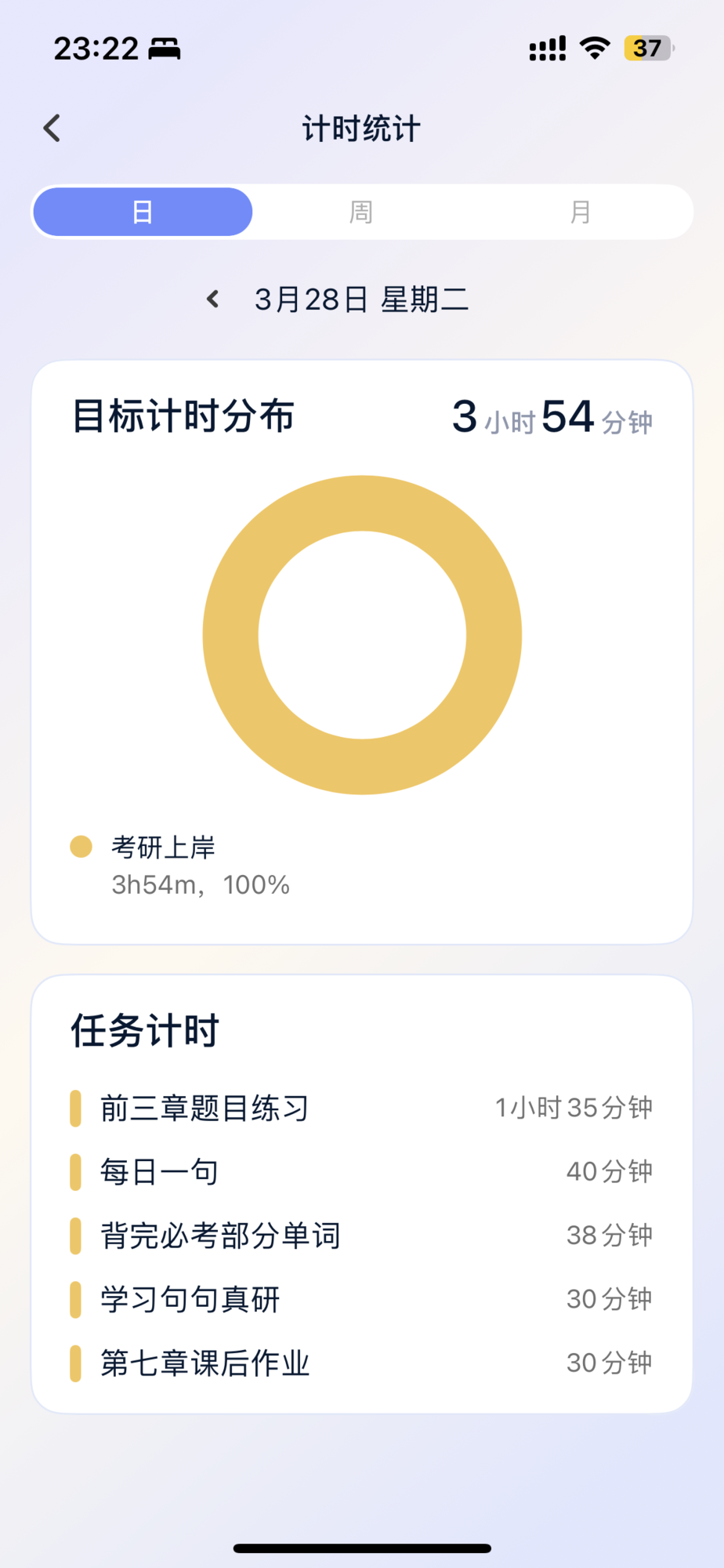
今天的学习
今天有点心得想要发一发复盘,今天主要就是在学英语和编程。今天依旧是受困于虽然学了编程语言但是不会用的痛苦。从某种程度来说,编程和英语是一样的思维,都是属于技能学习,而人类学习技能往往只能是通过不断反复的练习习得。今天emo搜索这个学了编程语言但是不会写编程题时,看到一个人的博客上写到,对于编程的学习,我们常常以为是资料的质量不够,其实事实并非这样,而是量不够。量变自然引起质变。一下子让我联想到chatGPT和语言大模型,也联想到人类关于学习这件事本身。
就目前揭露的数据,chatGPT大约有一千七百多亿参数,这正是一直量变引起质变的变化,而是就是在学习领域上。大学四年我一直觉得自己似乎无法踏实下来,真正的沉下心去琢磨花时间打磨自己的能力,更喜欢去做一些表面,能够通过搜索引擎或者目前丰富的互联网资料得到的事情,也因此常常感到焦虑,被大量热点包围,但是个人又缺乏经验的认知下,过载的信息带给人沉重的窒息感,如果将熵这个概念引入社会信息上,我觉得chatGPT的出现不仅仅是一个技术变革,对人类本身的思想、哲学、价值层面的冲击将是一种引爆。
换句话说,以我自身如此痛苦的学习感受为例,如果我们随时随地能够拥有chatCPT这样对我们而言是工具,而对互联网信息而言类似于全知全能的“神”的存在。信息可以说是在塑造着人,以前我们不清楚人机共生与人机融合到底是什么样,现在即将变得清晰,一旦习惯使用并且擅长用chatGPT,等同于真正的扩展第二个大脑,我们负责察觉与提问。自己吸收知识如此艰难的情况下,让chatGPT成为搜索引擎2.0,那也便意味着,离开它就等同于断了四肢。那么会不会出现,我们这种学习方式是古老的学习,就像是正在被遗弃的非遗一样?以后的人或许会疑惑,明明有了一个外挂的助手,为什么还要自己练?
成长带来的好处就是我能够耐得住性子克服焦虑去踏实一点点练习,将能力和模型真正训练进我的脑子里,主动筛寻信息,花大把大把的时间去理解内化与感悟。或许未来会出现,大模型大规模应用场景下类似信息茧房之于推荐算法的词汇描绘离开大模型就不会工作的现象。
今天有点心得想要发一发复盘,今天主要就是在学英语和编程。今天依旧是受困于虽然学了编程语言但是不会用的痛苦。从某种程度来说,编程和英语是一样的思维,都是属于技能学习,而人类学习技能往往只能是通过不断反复的练习习得。今天emo搜索这个学了编程语言但是不会写编程题时,看到一个人的博客上写到,对于编程的学习,我们常常以为是资料的质量不够,其实事实并非这样,而是量不够。量变自然引起质变。一下子让我联想到chatGPT和语言大模型,也联想到人类关于学习这件事本身。
就目前揭露的数据,chatGPT大约有一千七百多亿参数,这正是一直量变引起质变的变化,而是就是在学习领域上。大学四年我一直觉得自己似乎无法踏实下来,真正的沉下心去琢磨花时间打磨自己的能力,更喜欢去做一些表面,能够通过搜索引擎或者目前丰富的互联网资料得到的事情,也因此常常感到焦虑,被大量热点包围,但是个人又缺乏经验的认知下,过载的信息带给人沉重的窒息感,如果将熵这个概念引入社会信息上,我觉得chatGPT的出现不仅仅是一个技术变革,对人类本身的思想、哲学、价值层面的冲击将是一种引爆。
换句话说,以我自身如此痛苦的学习感受为例,如果我们随时随地能够拥有chatCPT这样对我们而言是工具,而对互联网信息而言类似于全知全能的“神”的存在。信息可以说是在塑造着人,以前我们不清楚人机共生与人机融合到底是什么样,现在即将变得清晰,一旦习惯使用并且擅长用chatGPT,等同于真正的扩展第二个大脑,我们负责察觉与提问。自己吸收知识如此艰难的情况下,让chatGPT成为搜索引擎2.0,那也便意味着,离开它就等同于断了四肢。那么会不会出现,我们这种学习方式是古老的学习,就像是正在被遗弃的非遗一样?以后的人或许会疑惑,明明有了一个外挂的助手,为什么还要自己练?
成长带来的好处就是我能够耐得住性子克服焦虑去踏实一点点练习,将能力和模型真正训练进我的脑子里,主动筛寻信息,花大把大把的时间去理解内化与感悟。或许未来会出现,大模型大规模应用场景下类似信息茧房之于推荐算法的词汇描绘离开大模型就不会工作的现象。
0 00
最近的学习和思考成果,尤其是在最近chatGPT的出现,重新思考,设计到底是什么?我们需要什么样的AI产品?
当我们谈论设计时,到底是在说什么?
1 00
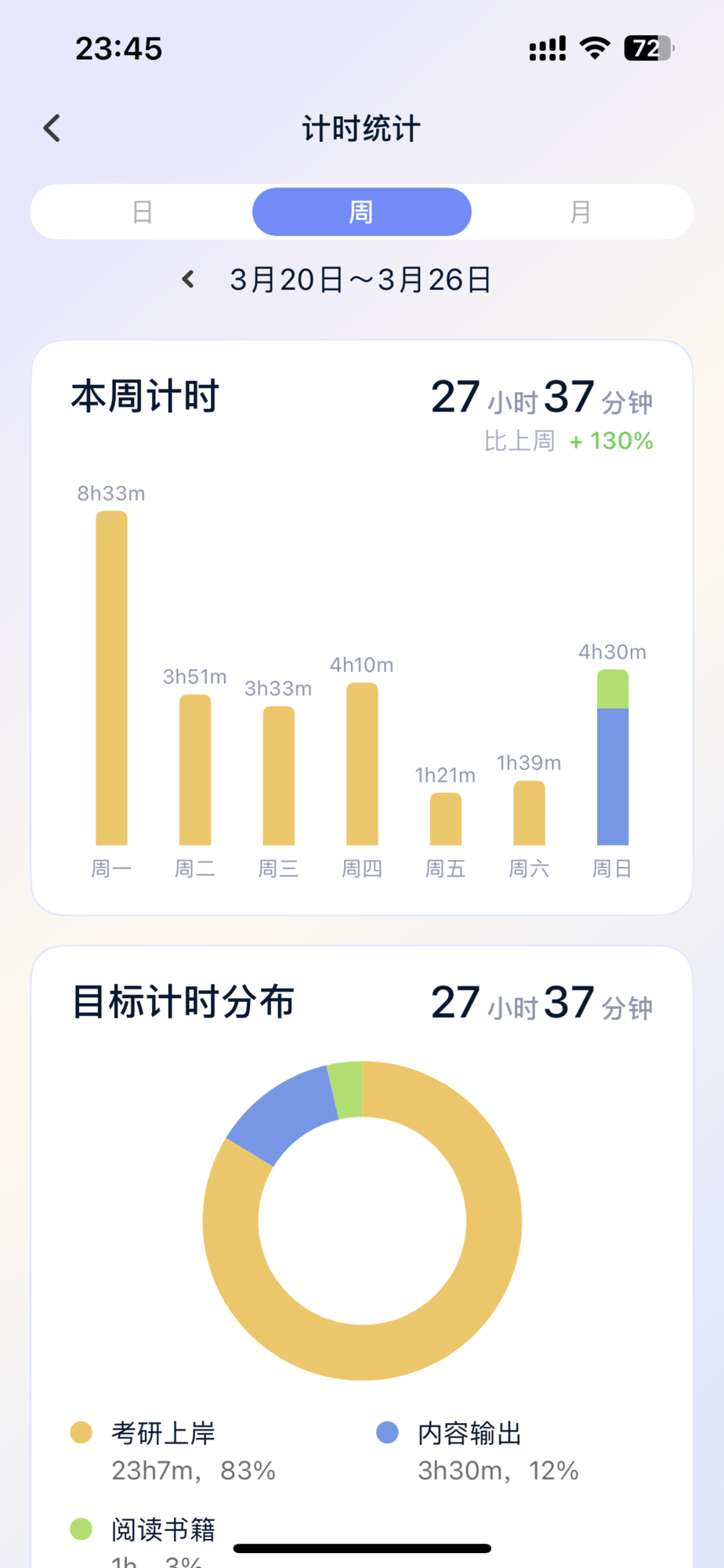
本周的学习结束啦,写写复盘总结
比上周时间提升不少,作为在职考研党已经很满意这个平时周内的学习时长了,但是问题在于周末的时间有效利用率有点低,容易把时间放在那些被诱惑而非我本身想做的事情上,比如刷视频,刷购物软件但不购物等等。
综合来说,周末还是非常充实与快乐的,希望以后还是能改善一下,多出去运动运动,匀一些时间去阅读,做内容的输出或许会更好。
本周写了关于设计概念的理解,算是总算是完成了一篇推文,个人很满意,因为这代表我迈开了腿,完成了从输入到输出的闭环,当然其中还有很多不完善的地方,比如说推文的排版不好,内容的输出形式可以拓展,当然以后会慢慢改进,最重要的是,终于初步构建出了这样的一个闭环。
还有很多其他的触动,比如周六看了玲芽之旅,周五换了一条新路,一路上发现了很多有趣的东西,比如体验了游戏厅的vr游戏,思考了非常多对人本身的理解。还听了关于硅谷银行的播客,收获了有价值的关于银行信任和创业者存钱的双备份的技巧……
下周也是不断进步的一周,有两个主题的需要考虑,另外关于英语和编程的学习与练习要继续,对于这种技能学习,我不是很擅长,我需要探索如何提高改进对这类知识的吸收。
比上周时间提升不少,作为在职考研党已经很满意这个平时周内的学习时长了,但是问题在于周末的时间有效利用率有点低,容易把时间放在那些被诱惑而非我本身想做的事情上,比如刷视频,刷购物软件但不购物等等。
综合来说,周末还是非常充实与快乐的,希望以后还是能改善一下,多出去运动运动,匀一些时间去阅读,做内容的输出或许会更好。
本周写了关于设计概念的理解,算是总算是完成了一篇推文,个人很满意,因为这代表我迈开了腿,完成了从输入到输出的闭环,当然其中还有很多不完善的地方,比如说推文的排版不好,内容的输出形式可以拓展,当然以后会慢慢改进,最重要的是,终于初步构建出了这样的一个闭环。
还有很多其他的触动,比如周六看了玲芽之旅,周五换了一条新路,一路上发现了很多有趣的东西,比如体验了游戏厅的vr游戏,思考了非常多对人本身的理解。还听了关于硅谷银行的播客,收获了有价值的关于银行信任和创业者存钱的双备份的技巧……
下周也是不断进步的一周,有两个主题的需要考虑,另外关于英语和编程的学习与练习要继续,对于这种技能学习,我不是很擅长,我需要探索如何提高改进对这类知识的吸收。
7 20
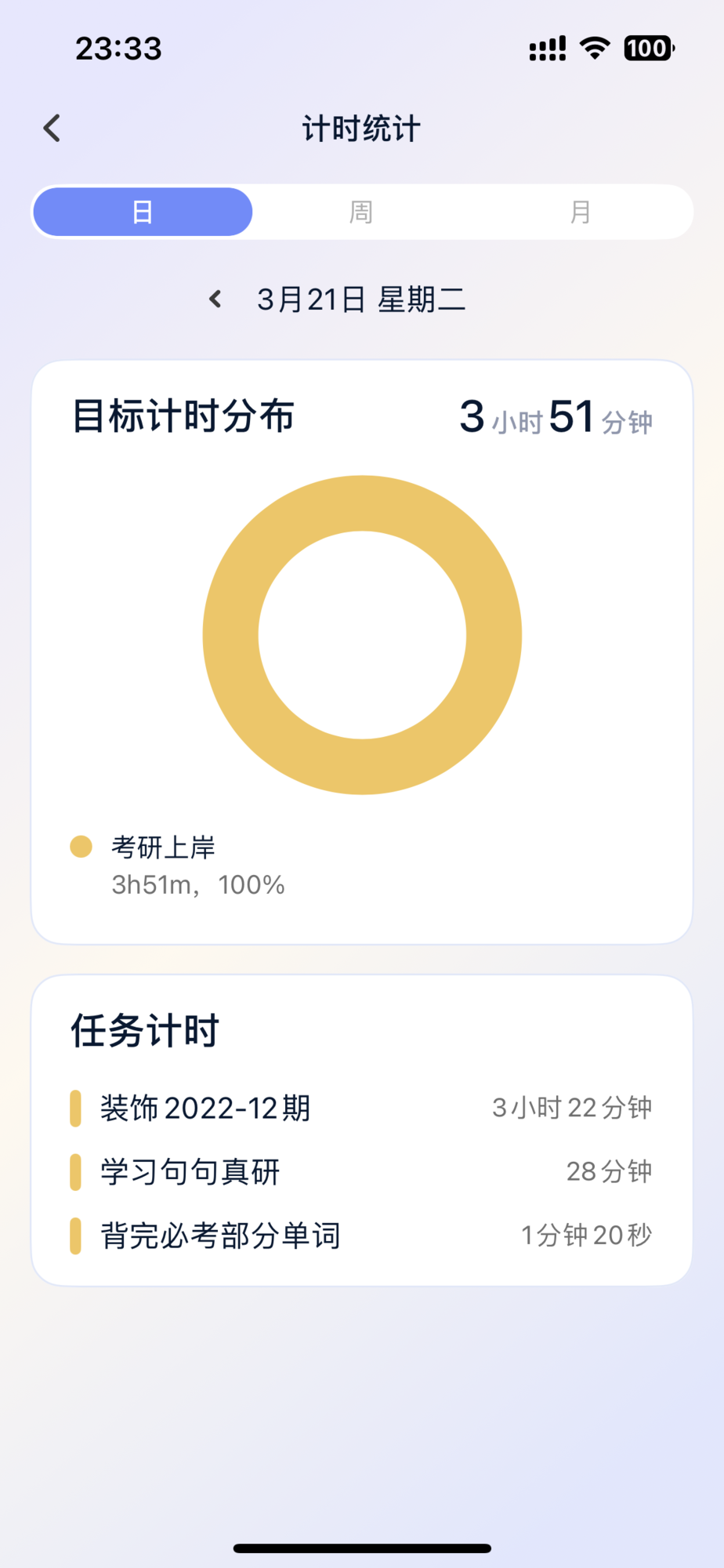
3月21日的小记
今天的收获还是满满的,而且有在积极调整学习策略。
今天最大的收获就是看的论文,关于富春山居数字文化体验馆设计的分析,提到了这个体验馆不同于传统的文旅产品,这是一直全效体验式数字文旅产品,说起来很拗口,其实很道理并不那么复杂。
传统的广义上的文旅产品主要是我们经常旅游看到的那种卖纪念品的店铺出售的产品,而这个所谓的全效体验式数字文旅产品可以理解为是一直体验消费,这篇论文就是在讲这个体验馆的设计构思和设计实践,希望能通过这个解读,给其他地方的数字化文旅产品设计带来思路。
就我自己的经验和观察来看,我觉得确实具有一点的价值和意义,我去过陕西省博物馆三四次了,但是不得不说,除非我有钱请个专门的讲解员或者我租赁那个电子讲解器,否则以我浅显的学识只够鉴赏文物的表面。而这个体验馆的设计里面,有很多巧思,比如利用大数据统计与富春山居有关的文化典故都有什么,分别出自哪里,都与哪些故事相关。这种利用数字技术去做单个文物的延伸是非常有趣的,另外比较常见的设计,在文物旁边放二维码或是NFC可以读取到相关的鉴赏及其价值,让人的体验确是大不相同。
第二个我觉得很有借鉴的意义在于,这个体验馆除了立足于某个文物,更是将该地的信息做了融合展示,打破了常规限制,当然这个设计尤其是对当地的文化底蕴不那么丰富的时候,做这样的深度和关联创作更有效。
最后,为什么我们需要做数字文旅产品呢?从商业角度考虑,这种经济就是一直绿色低碳经济,城市吸引更多的游客前来消费,该地政府获得更多的税收,不需要盖地建厂生产,仅仅是通过人口的流动就可以获得巨大的现金流,经济学的基本现象,你的消费就是别人的收入,最怕的便是不消费,社会进入不消费,那就无法流动,便有人要挨饿和产生动荡,因此从这个角度看,文旅就是重大的低碳经济的一部分。
关于C++,我已经调整了计划,从前两次的习题入重新去做,努力练习,无他法,唯手熟尔。
今天的收获还是满满的,而且有在积极调整学习策略。
今天最大的收获就是看的论文,关于富春山居数字文化体验馆设计的分析,提到了这个体验馆不同于传统的文旅产品,这是一直全效体验式数字文旅产品,说起来很拗口,其实很道理并不那么复杂。
传统的广义上的文旅产品主要是我们经常旅游看到的那种卖纪念品的店铺出售的产品,而这个所谓的全效体验式数字文旅产品可以理解为是一直体验消费,这篇论文就是在讲这个体验馆的设计构思和设计实践,希望能通过这个解读,给其他地方的数字化文旅产品设计带来思路。
就我自己的经验和观察来看,我觉得确实具有一点的价值和意义,我去过陕西省博物馆三四次了,但是不得不说,除非我有钱请个专门的讲解员或者我租赁那个电子讲解器,否则以我浅显的学识只够鉴赏文物的表面。而这个体验馆的设计里面,有很多巧思,比如利用大数据统计与富春山居有关的文化典故都有什么,分别出自哪里,都与哪些故事相关。这种利用数字技术去做单个文物的延伸是非常有趣的,另外比较常见的设计,在文物旁边放二维码或是NFC可以读取到相关的鉴赏及其价值,让人的体验确是大不相同。
第二个我觉得很有借鉴的意义在于,这个体验馆除了立足于某个文物,更是将该地的信息做了融合展示,打破了常规限制,当然这个设计尤其是对当地的文化底蕴不那么丰富的时候,做这样的深度和关联创作更有效。
最后,为什么我们需要做数字文旅产品呢?从商业角度考虑,这种经济就是一直绿色低碳经济,城市吸引更多的游客前来消费,该地政府获得更多的税收,不需要盖地建厂生产,仅仅是通过人口的流动就可以获得巨大的现金流,经济学的基本现象,你的消费就是别人的收入,最怕的便是不消费,社会进入不消费,那就无法流动,便有人要挨饿和产生动荡,因此从这个角度看,文旅就是重大的低碳经济的一部分。
关于C++,我已经调整了计划,从前两次的习题入重新去做,努力练习,无他法,唯手熟尔。
0 20
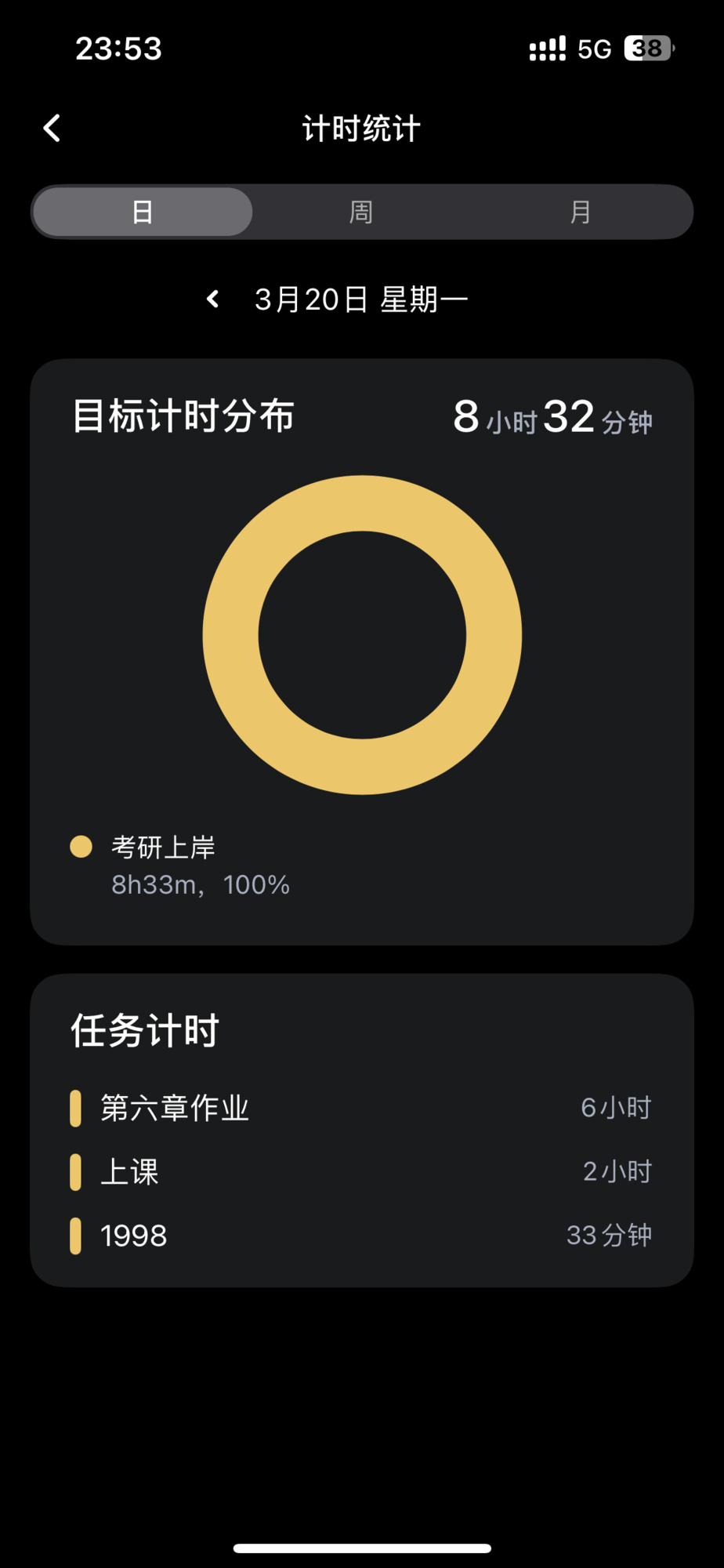
今日份的学习
今日状态:在emo与振奋中徘徊
在职考研太难了,但是我很幸运,今天摸鱼学习了六个小时,钻研C++数字与指针的知识和作业,很emo,感觉好难,一动手写题就啥啥都不会,脑袋空空,只能去抄答案,边抄边理解。
导致我今天心情一直不佳,怀疑自己,赶紧自己被狠狠抛下,即使知道这其实只是我认知的一种特点,偏好利用现状预见未来。
控制不住得去思考,世界变化如此之快,我确为了这一张入场券消磨一年时间,甚至我很可能很可能竹篮打水一场空,真得值得嘛?
但是冷静下来仔细去分析便会发现,我对价值的拷问本质上是源于挫折伤害了我的人格中的自恋,为了保护自己,大脑倾向于去找借口寻求拷问灵魂意义,以此来为自己开脱。自恋属性是人本身固有且最高的属性,在情绪主导时候,我们很难调用反思层的认知去干预。即使很浅显的道理,我们本身就知晓的,在此时也会被选择性的屏蔽,从自我剖析角度,这个现状很有趣,并且在反反复复出现在我的生活中。
总之,一切事物的存在不一定需要价值来构建,或许只是想把内心的一种渴望得到在现实的映射,当思考价值时候,值得我们深思,这纠结是一种自我逃避还是被现实蒙蔽。
明天加油,明天也要好好学习,并且做一些感想记录。
今日状态:在emo与振奋中徘徊
在职考研太难了,但是我很幸运,今天摸鱼学习了六个小时,钻研C++数字与指针的知识和作业,很emo,感觉好难,一动手写题就啥啥都不会,脑袋空空,只能去抄答案,边抄边理解。
导致我今天心情一直不佳,怀疑自己,赶紧自己被狠狠抛下,即使知道这其实只是我认知的一种特点,偏好利用现状预见未来。
控制不住得去思考,世界变化如此之快,我确为了这一张入场券消磨一年时间,甚至我很可能很可能竹篮打水一场空,真得值得嘛?
但是冷静下来仔细去分析便会发现,我对价值的拷问本质上是源于挫折伤害了我的人格中的自恋,为了保护自己,大脑倾向于去找借口寻求拷问灵魂意义,以此来为自己开脱。自恋属性是人本身固有且最高的属性,在情绪主导时候,我们很难调用反思层的认知去干预。即使很浅显的道理,我们本身就知晓的,在此时也会被选择性的屏蔽,从自我剖析角度,这个现状很有趣,并且在反反复复出现在我的生活中。
总之,一切事物的存在不一定需要价值来构建,或许只是想把内心的一种渴望得到在现实的映射,当思考价值时候,值得我们深思,这纠结是一种自我逃避还是被现实蒙蔽。
明天加油,明天也要好好学习,并且做一些感想记录。
35 63
p1~p4去图书馆门口正好有个展厅,展出女性关于敦煌的书画作品,非常喜欢这几副,因为这几幅很有趣,有趣在菩萨的表情并非是清一色的高冷,而是带有着灵动的表情,p2是关于供养人的作品,很喜欢这种人为视角的画,每个普通的供养人与菩萨一样值得被记录。
p5是一个有趣我很喜欢的,想象中的具有水榭、餐厅以及舞台的地方,然而明明是极佳的进食场景设计,确一人皆无。这些反差引起深思,商业与运营对这个社会产生了多大的影响?似乎我也已然变成了如果不看评价,不敢涉足于任何一家从未去过的饭店。为什么渐渐做出抉择变得如此困难,而我们身边无处不在有着抉择。
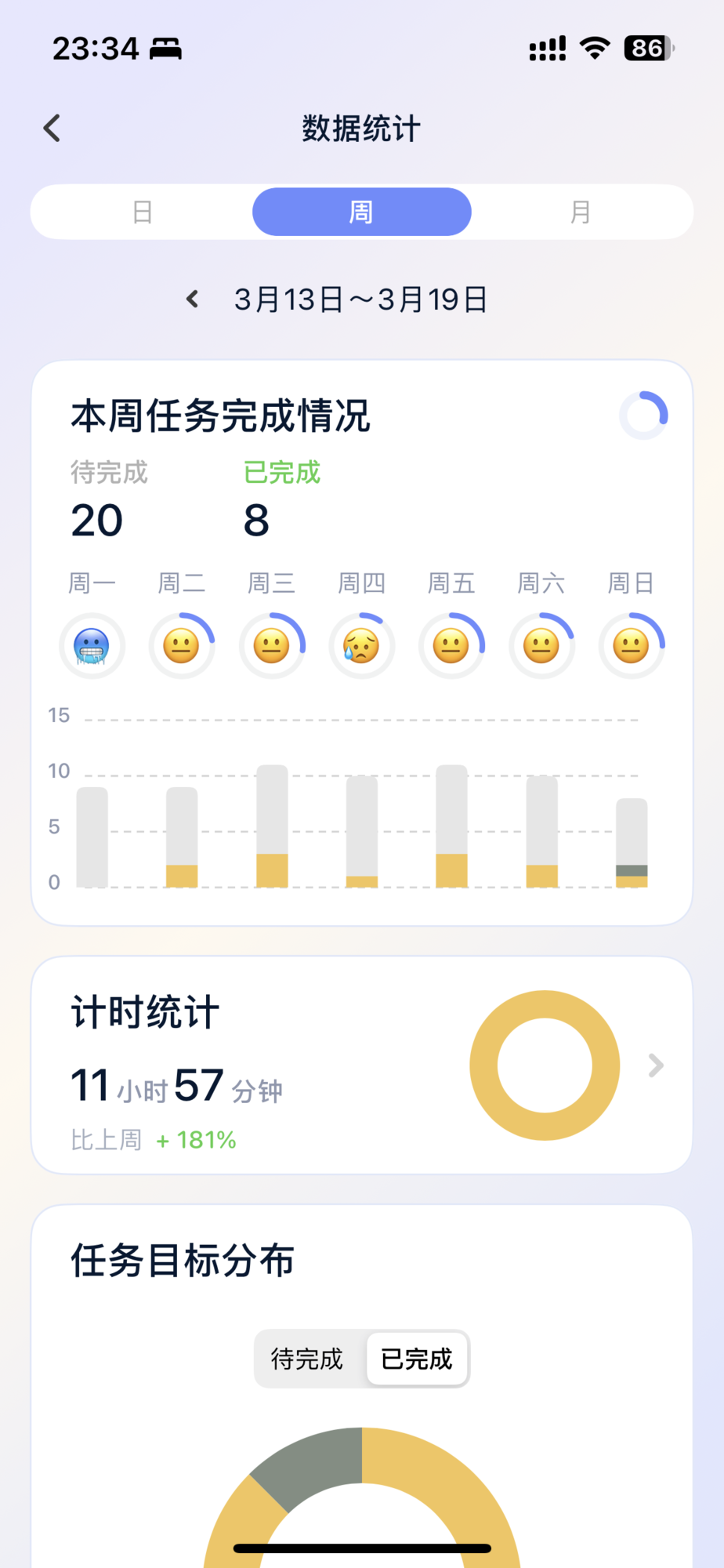
p6是这周的学习时间情况,这周的学习略差强人意,但是我在做积极改变了,首先就是记录数据,这样我才能分析得到,我纠结还缺乏什么,我需要在哪方面进行提升。
最后,之所以我要开始发布,我想清楚了一件事,如果我想要获得更好的观点,我需要参与到表述,积累案例不是一种单纯机械的摘抄,而是转换成自己的思考与语言,与同伴交换看法。所以我需要多去表达我的认知,练习本身就是一种学习。
p5是一个有趣我很喜欢的,想象中的具有水榭、餐厅以及舞台的地方,然而明明是极佳的进食场景设计,确一人皆无。这些反差引起深思,商业与运营对这个社会产生了多大的影响?似乎我也已然变成了如果不看评价,不敢涉足于任何一家从未去过的饭店。为什么渐渐做出抉择变得如此困难,而我们身边无处不在有着抉择。
p6是这周的学习时间情况,这周的学习略差强人意,但是我在做积极改变了,首先就是记录数据,这样我才能分析得到,我纠结还缺乏什么,我需要在哪方面进行提升。
最后,之所以我要开始发布,我想清楚了一件事,如果我想要获得更好的观点,我需要参与到表述,积累案例不是一种单纯机械的摘抄,而是转换成自己的思考与语言,与同伴交换看法。所以我需要多去表达我的认知,练习本身就是一种学习。





0 00