即刻App年轻人的同好社区
下载
Self-Refine:通过针对性地反馈 (Feedback) 调整循环来引导 AI 输出更好的答案。
上周吴恩达教授在 The Batch 中聊到了智能体 (AI Agent) 工作流设计模式中的反思模式 (m.okjike.com),并推荐了三篇论文:
- Self-Refine (arxiv.org)
- Reflexion (arxiv.org)
- CRITIC (arxiv.org)
读下来对我启发最大的是 Self-Refine,也是我认为能够在日常与 AI 对话中可以直接用得上的。如果你的工作会涉及到智能体 (AI Agent) 的工作流,Reflexion 和 CRITIC 可以参考一下,对于日常使用 AI 来说,不读问题也不大。模式都比较好理解,难的是工程上如何针对性地应用。
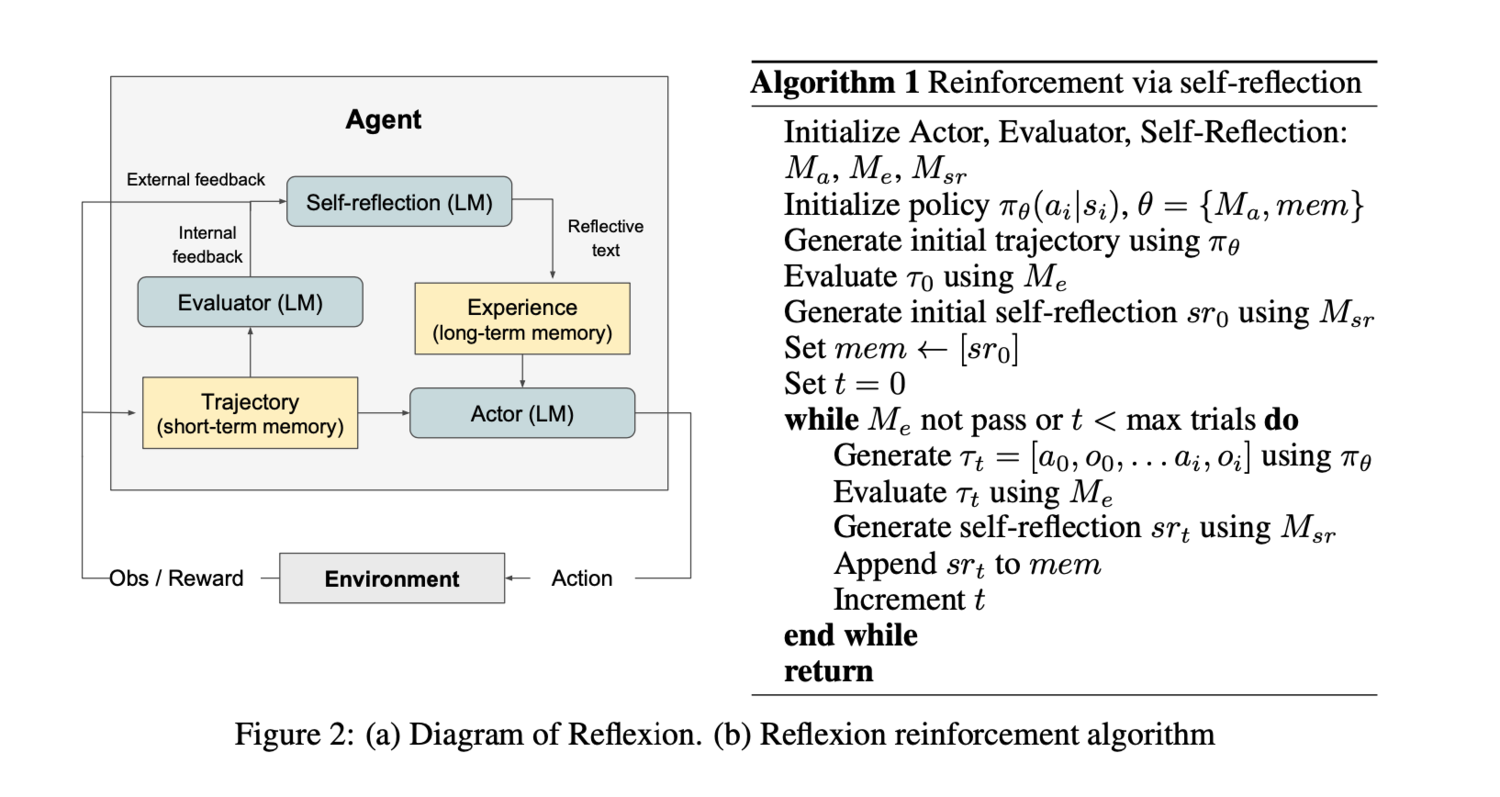
其中,Reflexion 的模式是有三个主要的角色加一个记忆模块 (Memory) 来实现:
1. 执行者(Actor):就像一个尝试解决问题的人,它会根据当前的情况提出行动计划,并执行这些计划;
2. 评估者(Evaluator):类似于一个老师或评委,它会评估执行者的行动计划是否有效,并给出成绩或反馈;
3. 反思者(Self-reflection):当执行者的计划不够好时,反思者会帮助它理解哪里出了问题,并提出如何改进的建议。
就像人类在犯错后会思考如何改进一样,这个过程中,Actor 会尝试不同的行动,并从结果中学习。每当 Actor 完成一个步骤时,Evaluator 会评估 Actor 的表现,并记录下哪些做得好,哪些需要改进。这些记录被保存起来放到 Memory 模块中,以便在未来的尝试中让 Actor 参考,并在未来做出更好的决策。通过这样的尝试、评估和反思循环来更好地完成指定的任务。
整个过程参考图一。
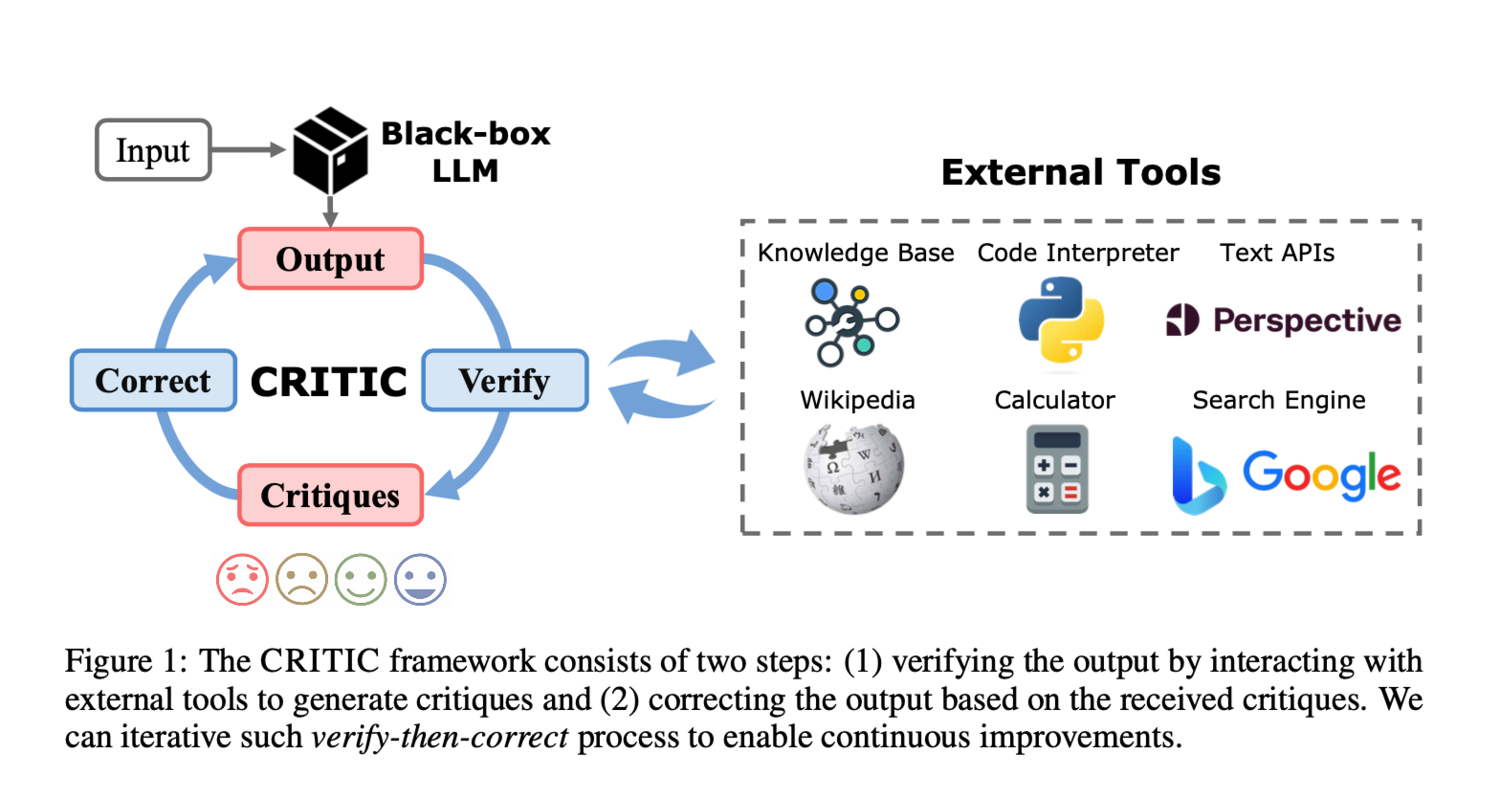
CRITIC 则更好理解,就是借助外部工具来给 AI 提供更精确的反馈,然后让 AI 根据这些反馈来优化输出。过程大致如下:
AI 输出答案以后,借助适当的外部工具(如搜索引擎、代码解释器等)来验证答案中的某些环节,比如可以通过搜索引擎或者文档资料来验证事实性信息,或者通过代码解释器来执行 AI 生成的代码是否能够正常运行等。同时将验证后的结果形成反馈信息再发送给 AI,让其根据反馈来修正输出。重复这个验证和修正的循环,直到满足特定的停止条件。
整个过程参考图二。
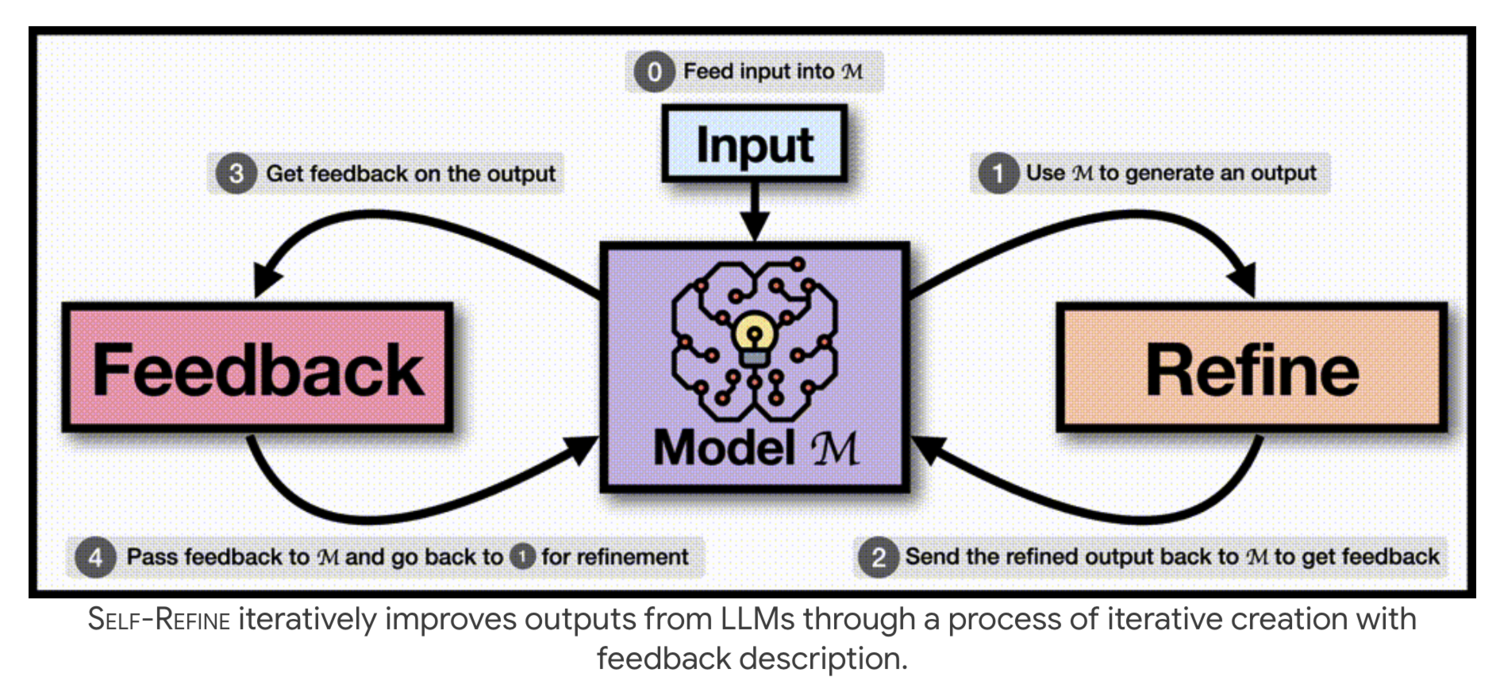
Self-Refine 方法则更容易理解,其核心是两个相互交替的步骤:Feedback(反馈)和 Refine(优化)。就是让 AI 自己对自己的答案进行评估并给出针对性的反馈,这些反馈不仅指出了问题所在,还提供了改进的方向。
然后引导 AI 根据这些 Feedback(反馈)来调整输出,也就是 Refine 步骤。这一过程可以重复多次,直到输出达到满意的质量标准。
整个过程参考图三。
即使这个过程不自动化,对于我们日常使用来说,也有很大价值。当 AI 的输出不符合我们的预期的时候,除了考虑要拆分子任务之外,另外很重要的一点就是指出 AI 的回复中具体的问题,告诉它哪里哪里不好,为什么不好,应该如何等。这就是我们在主动提供 Feedback(反馈)。
Self-Refine 的方式是让 AI 自己给自己 Feedback(反馈),其对我最大的启发是:要针对具体任务设计 Feedback 原则。
论文中针对对话设计的 Feedback 原则是从 Relevant(相关性)、Informative(信息量)、Engaging(吸引人的)等方面来引导 AI 给出反馈;而针对代码生成任务则是从效率(Efficiency)、可读性(Readability)、准确性(Accuracy)等方面来生成反馈。
这种思路是不是可以借鉴到我们用 AI 完成其他日常任务呢?
举个例子,当我们觉得 AI 英译中的结果不够好时,简单的方式可以是让其用某种文章内容相关的角色来进行润色,或者让其自己反思翻译结果有什么问题再重新翻译。
那如果按照 Self-Refine 中的 Feedback 原则,在让 AI 反思的时候,指出具体的反思方向会不会更好呢?比如可以从准确性(Accuracy)、流畅性(Fluency)、语法正确性(Grammar Correctness)、词汇恰当性(Lexical Appropriateness)、文化适应性(Cultural Adaptation)、风格一致性(Style Consistency)、目标受众(Target Audience Suitability)等方面来对翻译结果给出反馈,这样是不是能得到更好的结果呢?
当然,Self-Refine 要能够有效,首先 AI 本身的能力要足够强,否则 AI 得不出有价值的反馈。另外要注意的就是论文的测试结果都是基于英文的数据集。不过没关系,试试这种思路没什么损失,我相信起码不会得到更差的结果。
我会在接下来翻译 The Batch 的时候尝试一下这个方式。
上周吴恩达教授在 The Batch 中聊到了智能体 (AI Agent) 工作流设计模式中的反思模式 (m.okjike.com),并推荐了三篇论文:
- Self-Refine (arxiv.org)
- Reflexion (arxiv.org)
- CRITIC (arxiv.org)
读下来对我启发最大的是 Self-Refine,也是我认为能够在日常与 AI 对话中可以直接用得上的。如果你的工作会涉及到智能体 (AI Agent) 的工作流,Reflexion 和 CRITIC 可以参考一下,对于日常使用 AI 来说,不读问题也不大。模式都比较好理解,难的是工程上如何针对性地应用。
其中,Reflexion 的模式是有三个主要的角色加一个记忆模块 (Memory) 来实现:
1. 执行者(Actor):就像一个尝试解决问题的人,它会根据当前的情况提出行动计划,并执行这些计划;
2. 评估者(Evaluator):类似于一个老师或评委,它会评估执行者的行动计划是否有效,并给出成绩或反馈;
3. 反思者(Self-reflection):当执行者的计划不够好时,反思者会帮助它理解哪里出了问题,并提出如何改进的建议。
就像人类在犯错后会思考如何改进一样,这个过程中,Actor 会尝试不同的行动,并从结果中学习。每当 Actor 完成一个步骤时,Evaluator 会评估 Actor 的表现,并记录下哪些做得好,哪些需要改进。这些记录被保存起来放到 Memory 模块中,以便在未来的尝试中让 Actor 参考,并在未来做出更好的决策。通过这样的尝试、评估和反思循环来更好地完成指定的任务。
整个过程参考图一。
CRITIC 则更好理解,就是借助外部工具来给 AI 提供更精确的反馈,然后让 AI 根据这些反馈来优化输出。过程大致如下:
AI 输出答案以后,借助适当的外部工具(如搜索引擎、代码解释器等)来验证答案中的某些环节,比如可以通过搜索引擎或者文档资料来验证事实性信息,或者通过代码解释器来执行 AI 生成的代码是否能够正常运行等。同时将验证后的结果形成反馈信息再发送给 AI,让其根据反馈来修正输出。重复这个验证和修正的循环,直到满足特定的停止条件。
整个过程参考图二。
Self-Refine 方法则更容易理解,其核心是两个相互交替的步骤:Feedback(反馈)和 Refine(优化)。就是让 AI 自己对自己的答案进行评估并给出针对性的反馈,这些反馈不仅指出了问题所在,还提供了改进的方向。
然后引导 AI 根据这些 Feedback(反馈)来调整输出,也就是 Refine 步骤。这一过程可以重复多次,直到输出达到满意的质量标准。
整个过程参考图三。
即使这个过程不自动化,对于我们日常使用来说,也有很大价值。当 AI 的输出不符合我们的预期的时候,除了考虑要拆分子任务之外,另外很重要的一点就是指出 AI 的回复中具体的问题,告诉它哪里哪里不好,为什么不好,应该如何等。这就是我们在主动提供 Feedback(反馈)。
Self-Refine 的方式是让 AI 自己给自己 Feedback(反馈),其对我最大的启发是:要针对具体任务设计 Feedback 原则。
论文中针对对话设计的 Feedback 原则是从 Relevant(相关性)、Informative(信息量)、Engaging(吸引人的)等方面来引导 AI 给出反馈;而针对代码生成任务则是从效率(Efficiency)、可读性(Readability)、准确性(Accuracy)等方面来生成反馈。
这种思路是不是可以借鉴到我们用 AI 完成其他日常任务呢?
举个例子,当我们觉得 AI 英译中的结果不够好时,简单的方式可以是让其用某种文章内容相关的角色来进行润色,或者让其自己反思翻译结果有什么问题再重新翻译。
那如果按照 Self-Refine 中的 Feedback 原则,在让 AI 反思的时候,指出具体的反思方向会不会更好呢?比如可以从准确性(Accuracy)、流畅性(Fluency)、语法正确性(Grammar Correctness)、词汇恰当性(Lexical Appropriateness)、文化适应性(Cultural Adaptation)、风格一致性(Style Consistency)、目标受众(Target Audience Suitability)等方面来对翻译结果给出反馈,这样是不是能得到更好的结果呢?
当然,Self-Refine 要能够有效,首先 AI 本身的能力要足够强,否则 AI 得不出有价值的反馈。另外要注意的就是论文的测试结果都是基于英文的数据集。不过没关系,试试这种思路没什么损失,我相信起码不会得到更差的结果。
我会在接下来翻译 The Batch 的时候尝试一下这个方式。
28 123
来自圈子

AI探索站
114134人已经加入