即刻App年轻人的同好社区
下载
 置顶
置顶今天聚餐玩了个游戏,大家预先写一个自己最有趣的事情到纸上给HR,然后HR随机抽一张念一下,让大家猜是谁写的。
有一次,念了A写的内容之后,B很快就猜出来是A。后来B说,TA之前听A说起过这个事,可能已经比较久远了。
这让我想起来最近llm的一个评测,叫Needle in a haystack ,中文一般叫大海捞针。是不是很一致?不由感叹人类的大海捞针能力是真强。
不过,这东西在此之前是叫attention 吧😂,只不过是超长序列的attention 。
有一次,念了A写的内容之后,B很快就猜出来是A。后来B说,TA之前听A说起过这个事,可能已经比较久远了。
这让我想起来最近llm的一个评测,叫Needle in a haystack ,中文一般叫大海捞针。是不是很一致?不由感叹人类的大海捞针能力是真强。
不过,这东西在此之前是叫attention 吧😂,只不过是超长序列的attention 。
1 00
很有意思的一个讨论,大多数人都认为是token的问题,然而根据我的测试显示不是这样,他们能够搞清楚蜡烛的长度,但是搞错了蜡烛长度和被吹灭顺序的关系。
https://www.reddit.com/r/LocalLLaMA/comments/1bvx6cc/the_prompt_that_every_llm_gets_wrong
2 00
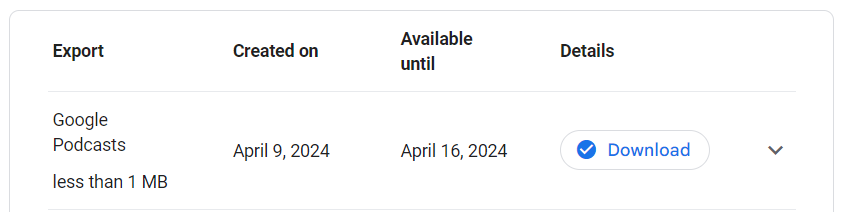
Google 播客即将于今年(2024)7 月关闭,目前有些人已经可以在 podcasts.google.com 上导出 opml 文件或者迁移到 YT music,但是很多人的页面上都没有这个选项。
此时你可以通过 Google Takeout 来导出:
1. 访问 takeout.google.com。
2. 选择 Google Podcasts。此时默认格式应该是 OPML,如果不是的话切换到 OPML。
3. 点击 Create Export。文件一般很小,本质上是一个 XML 文件,很快就可以导出了,几分钟后刷新一下页面,就不用去邮箱下载了。
4. 将得到 OPML 文件导入到你喜欢的 app 里。
5. Listen。
此时你可以通过 Google Takeout 来导出:
1. 访问 takeout.google.com。
2. 选择 Google Podcasts。此时默认格式应该是 OPML,如果不是的话切换到 OPML。
3. 点击 Create Export。文件一般很小,本质上是一个 XML 文件,很快就可以导出了,几分钟后刷新一下页面,就不用去邮箱下载了。
4. 将得到 OPML 文件导入到你喜欢的 app 里。
5. Listen。
1 00
如果你不喜欢reddit的最新版界面,那么可以使用这个chrome插件回退到旧版。
https://chromewebstore.google.com/detail/bfcldjodnnkndfccfjndmdlppfkmccgh
2 00
简单看了下最近又一个强大的 LLM:DBRX,databricks 出品,之前他们出了 dolly 系列模型,当时声称是世界上第一个 Truly Open Instruction-Tuned LLM,说到做到,公开数据集,公开代码,公开模型。
ok 说回 DBRX:
1. 这次放出了两个版本:base 和 instruct。
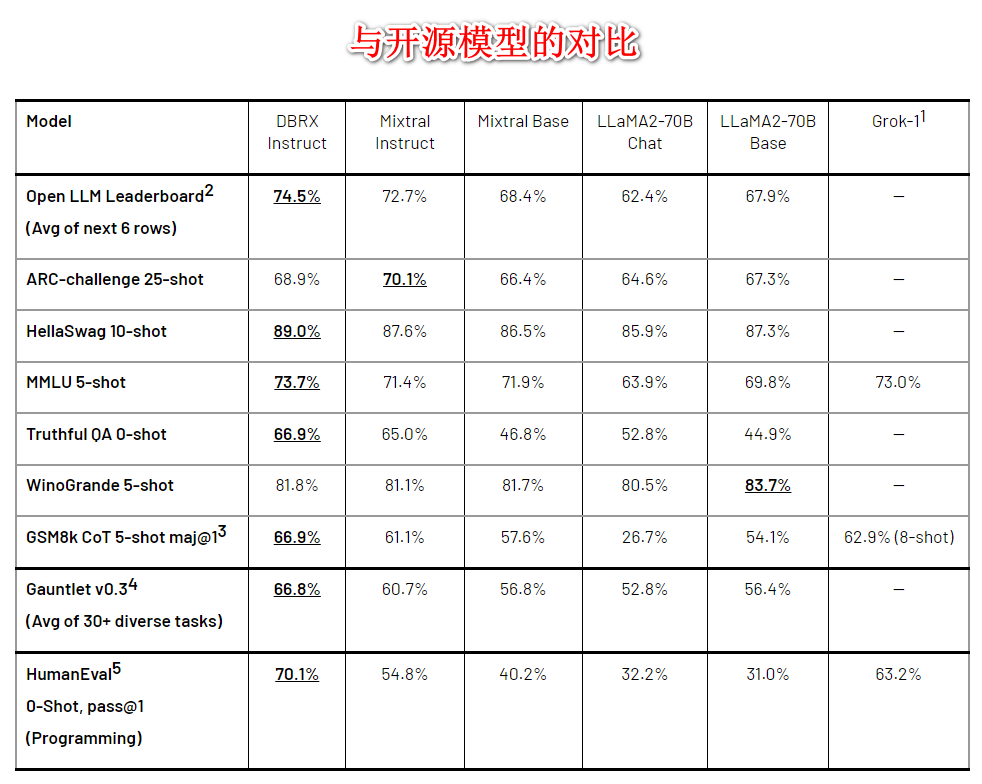
2. MoE 结构,参数量 132 B,4×33B,16个 fine-grained 专家模型,4个激活,Mixtral 和 Grok-1则是8/2。
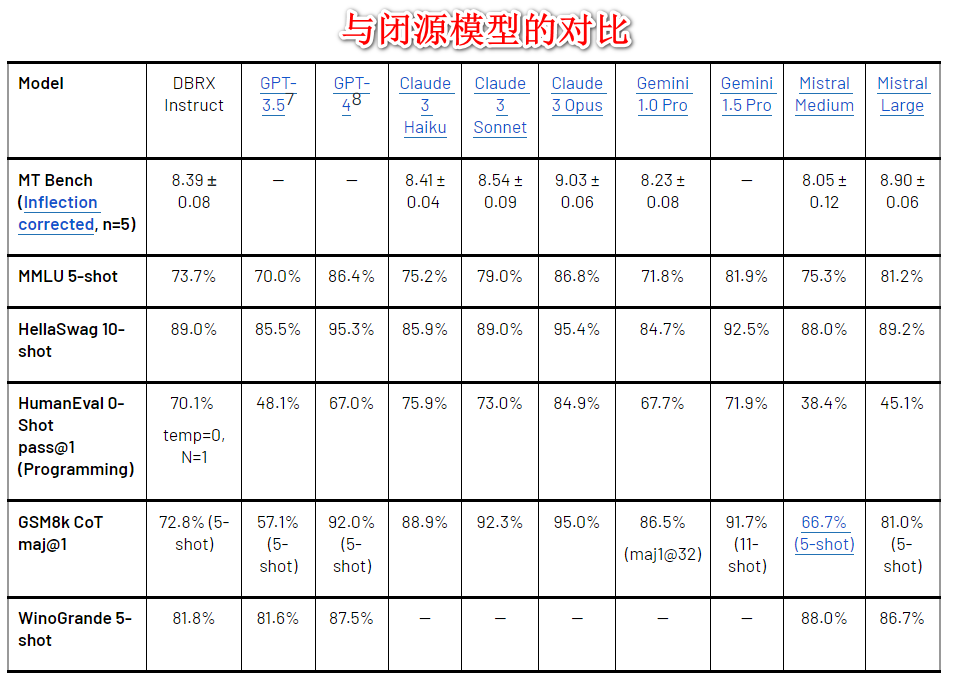
3. 超越 gpt3.5,competitive with Gemini 1.0 pro。
4. 由于 fine-grained 专家模型(更多更小),推理速度比 LLaMA2-70B 快 2 倍,在总参数和活跃参数计数方面大约是 Grok-1 的 40%。
5. 具体结构方面,RoPE + gated linear units (GLU) + grouped query attention (GQA) + GPT4 tokenizer(tiktoken)。
6. 使用3072 NVIDIA H100s 进行训练。
7. 整个流程(预训练、后训练、评估、红队测试和改进)持续了3个月。
8. 在 hf 上获取 base 权重需要人工审核,而且似乎很多人都还没通过。而 instruct 则是自动通过的。
9. 附图是与其他开源闭源模型在各种数据集上的评测对比。
www.databricks.com
ok 说回 DBRX:
1. 这次放出了两个版本:base 和 instruct。
2. MoE 结构,参数量 132 B,4×33B,16个 fine-grained 专家模型,4个激活,Mixtral 和 Grok-1则是8/2。
3. 超越 gpt3.5,competitive with Gemini 1.0 pro。
4. 由于 fine-grained 专家模型(更多更小),推理速度比 LLaMA2-70B 快 2 倍,在总参数和活跃参数计数方面大约是 Grok-1 的 40%。
5. 具体结构方面,RoPE + gated linear units (GLU) + grouped query attention (GQA) + GPT4 tokenizer(tiktoken)。
6. 使用3072 NVIDIA H100s 进行训练。
7. 整个流程(预训练、后训练、评估、红队测试和改进)持续了3个月。
8. 在 hf 上获取 base 权重需要人工审核,而且似乎很多人都还没通过。而 instruct 则是自动通过的。
9. 附图是与其他开源闭源模型在各种数据集上的评测对比。
www.databricks.com
3 00
早上我女儿站着尿尿,然后和她说要去马桶上蹲下来尿尿,她说“好”,这是她最近才学会的词。
然后根据经验,她接下来大概率还是会站着尿尿。她并没有理解“好”是什么意思。
让我想到了 llm ,它们在回复我们的时候,听起来很像话,但是它们并没有理解它们回复的意思,因为你让它不要这么说,它会说“好的”奉承你一下,然后接着做那不应该做的事。
然后根据经验,她接下来大概率还是会站着尿尿。她并没有理解“好”是什么意思。
让我想到了 llm ,它们在回复我们的时候,听起来很像话,但是它们并没有理解它们回复的意思,因为你让它不要这么说,它会说“好的”奉承你一下,然后接着做那不应该做的事。
2 00
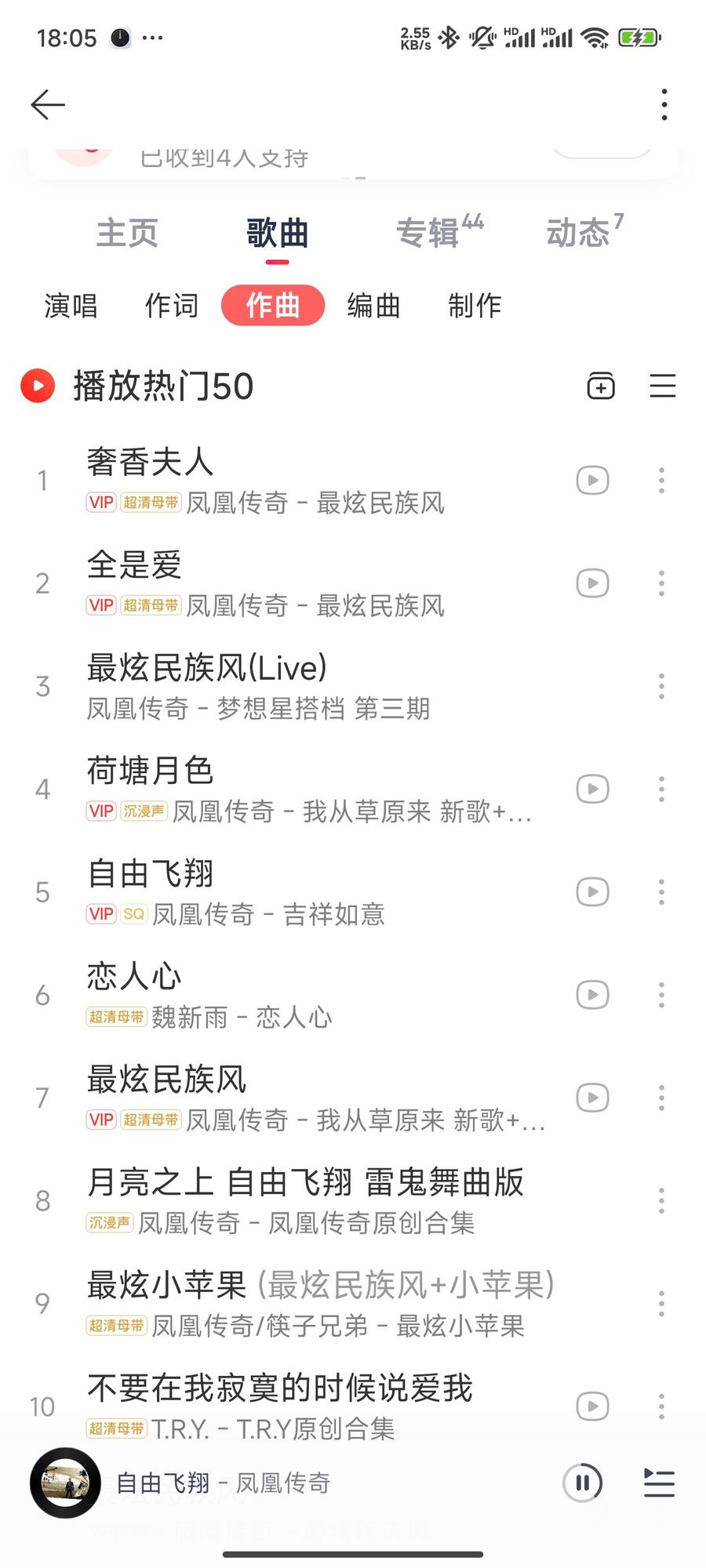
刚才在听凤凰传奇的《自由飞翔》,突然想看下词曲都是谁,看了下是张超,有点厉害,词曲包办,继续点进去看下。
嚯,90年的,而自由飞翔是07年发行的,也就是说他在17岁时词曲包办了这首歌!
再继续看下,凤凰传奇很多歌都是他词曲包办的,包括最炫民族风和荷塘月色等大热歌曲。
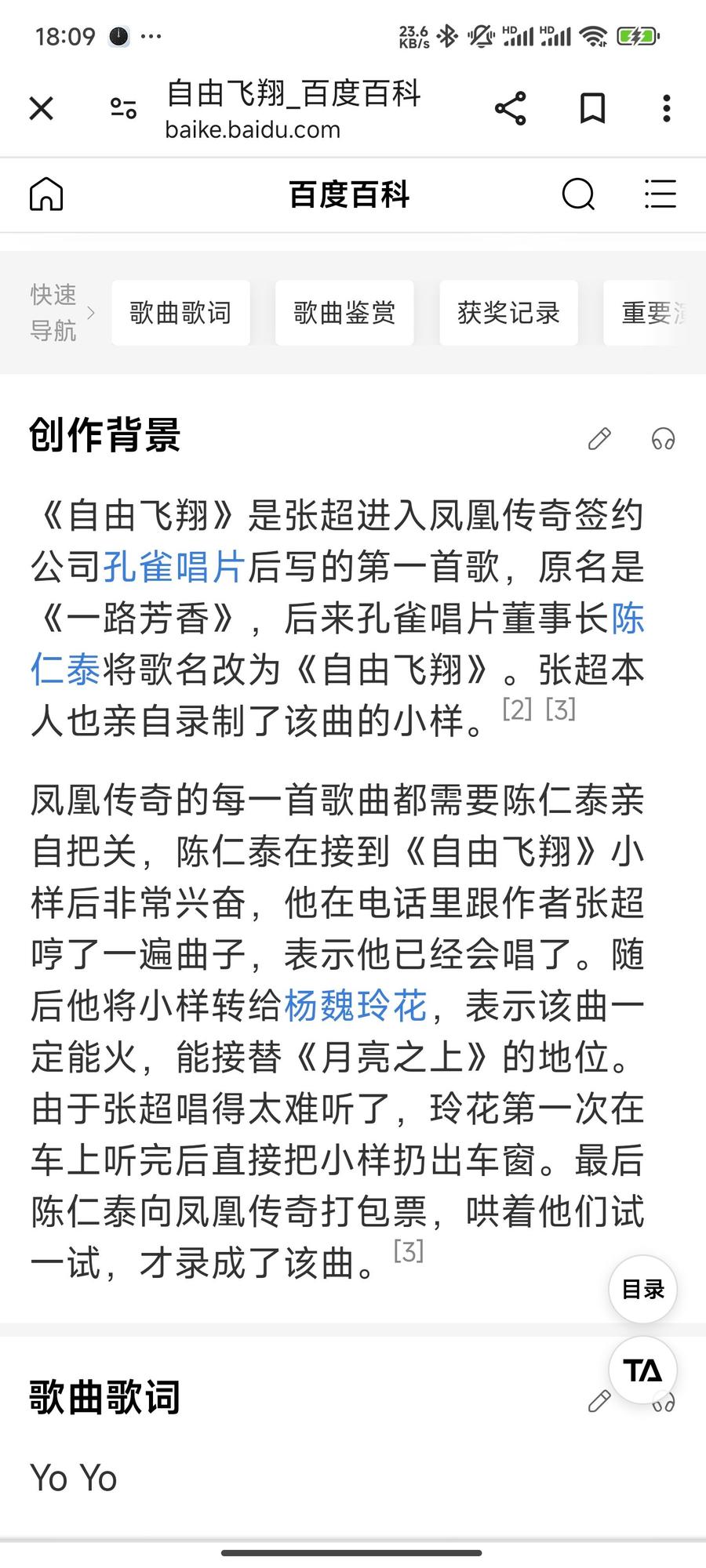
另外再补一下这首歌的创作背景(p4),有点搞笑😂
另另外,上春山也是他作曲。
嚯,90年的,而自由飞翔是07年发行的,也就是说他在17岁时词曲包办了这首歌!
再继续看下,凤凰传奇很多歌都是他词曲包办的,包括最炫民族风和荷塘月色等大热歌曲。
另外再补一下这首歌的创作背景(p4),有点搞笑😂
另另外,上春山也是他作曲。

2 00

最近发现两篇关于在家训练 LLM 的文章,觉得一起食用更佳:
1. Building a GPU Cluster at home:felix-red-panda.github.io,详细阐述了在家里构建 GPU 集群时需要考虑的各个方面,包括 PCIe 带宽、电力需求、电源选择、冷却需求、GPU 选择、内存需求、存储需求、软件配置以及通风和其他注意事项。它提供了建议和实用技巧,有助于读者构建高性能且可靠的家用 GPU 服务器。
2. You can now train a 70b language model at home:www.answer.ai,这是 Jeremy 与其他人一起开发的一个开源系统,可以在普通台式机上使用两块 24 GB 游戏显卡高效训练 70 亿参数的大型语言模型。该系统结合了 FSDP 和 QLoRA 两种技术。FSDP 可以将大型模型分片分布在多个 GPU 上并行训练,而 QLoRA 通过量化和低秩适配器(LoRA)减小模型尺寸使其能装载在较小显存的 GPU上。文章详细阐述了将这两种技术结合使用的技术细节和遇到的挑战,以及所采用的其他优化手段。该系统有望使训练大型AI模型的能力不再仅限于拥有昂贵数据中心 GPU 的大公司和机构,让普通个人和小型实验室也能参与创建自己的个性化模型。
总结起来就是 1 帮你搭建硬件环境,2 帮你解决软件环境,完美!
另外在读 2 的时候发现一个根据模型参数量(B)速算显存大小的方式:70B 参数,每个参数 2B(16bit),占用显存 140GB。所以就是模型参数量(B)×每个参数大小(Bytes)=模型所需显存大小(GB)。
1. Building a GPU Cluster at home:felix-red-panda.github.io,详细阐述了在家里构建 GPU 集群时需要考虑的各个方面,包括 PCIe 带宽、电力需求、电源选择、冷却需求、GPU 选择、内存需求、存储需求、软件配置以及通风和其他注意事项。它提供了建议和实用技巧,有助于读者构建高性能且可靠的家用 GPU 服务器。
2. You can now train a 70b language model at home:www.answer.ai,这是 Jeremy 与其他人一起开发的一个开源系统,可以在普通台式机上使用两块 24 GB 游戏显卡高效训练 70 亿参数的大型语言模型。该系统结合了 FSDP 和 QLoRA 两种技术。FSDP 可以将大型模型分片分布在多个 GPU 上并行训练,而 QLoRA 通过量化和低秩适配器(LoRA)减小模型尺寸使其能装载在较小显存的 GPU上。文章详细阐述了将这两种技术结合使用的技术细节和遇到的挑战,以及所采用的其他优化手段。该系统有望使训练大型AI模型的能力不再仅限于拥有昂贵数据中心 GPU 的大公司和机构,让普通个人和小型实验室也能参与创建自己的个性化模型。
总结起来就是 1 帮你搭建硬件环境,2 帮你解决软件环境,完美!
另外在读 2 的时候发现一个根据模型参数量(B)速算显存大小的方式:70B 参数,每个参数 2B(16bit),占用显存 140GB。所以就是模型参数量(B)×每个参数大小(Bytes)=模型所需显存大小(GB)。


2 01